基于Linux的集群系统(五)
出处:赛迪网 作者:赛迪网 时间:2006-10-12 10:43:00
实现过程之理论先导篇(2)
本篇是实现过程的第二个理论先导篇,作者将向我们讲述负载平衡机制的理论研究。
在计算机硬件价格下降、计算机网络拓扑发展的情况下,分布式计算机系统给用户提供了一个丰富的资源集合。人们在研究分布式系统时,就注意到了这样一个问题:在一个由网络连接起来的多计算机环境中,在某一时刻,一些计算机的负载比较重,而另外一些计算机的负载却比较轻。平衡各计算机之间的负载是任务分配与调度的一个主要目标,它能够提高整个系统的性能。
为了改善系统的性能,通过在多台计算机之间合理地分配负载,使各台计算机的负载基本均衡,这种计算能力共享的形式,通常被称为负载平衡或负载共享。一般来说,"负载平衡"要达到的目标是使各台计算机之间的负载基本均衡,而"负载共享"意味着只是简单的负载的重新分配。
负载平衡包括两种,一种是静态负载平衡,一种是动态负载平衡。只是利用系统负载的平均信息,而忽视系统当前的负载状况的方法被称为静态负载平衡。根据系统当前的负载状况来调整任务划分的方法被称为动态负载平衡。
导致负载不平衡主要是由于:
某些算法的迭代大小不是固定的,但迭代的大小在编译时却可以被求得;
某些算法的迭代大小不是固定的,并且迭代的大小依赖于被处理的数据,在编译时无法求得;
即使迭代大小是固定的,也会有许多不定因素导致计算速度的差异。
考察这三个原因,对第一种情况可在编译时估计各迭代的工作量,按照处理节点的处理能力分布迭代,这就是静态负载平衡的方法。对第二、三种情况来说,必须采用动态负载平衡的手段,在运行过程中根据各个处理节点完成任务的情况,动态地迁移任务,实现动态负载平衡。进行动态负载平衡需要考察处理节点的处理能力,它的基本依据是根据处理节点先前的处理速度预见未来的处理速度。
负载平衡算法
一个负载平衡算法都包含以下三个组成部分:
信息策略:制定任务放置策略的制定者使用的负载和任务量,以及信息分配的方式。
传送策略:基于任务和计算机负载,判断是否要把一个任务传送到其它计算机上处理。
放置策略:对于适合传送到其它计算机处理的任务,选择任务将被传送的目的计算机。
负载平衡的上述三个部分之间是以不同的方式相互作用的。放置策略利用信息策略提供的负载信息,仅当任务被传送策略判断为适于传送之后才行动。
总之,负载平衡的目标是:提供最短的平均任务响应时间;能适于变化的负载;是可靠的负载平衡机制。
信息策略
人们用来描述负载信息采用的参数有:
运行队列中的任务数;
系统调用的速率;
CPU上下文切换率;
空闲CPU时间百分比;
空闲存储器的大小(K字节);
1分钟内的平均负载。对于这些单个的负载描述参数,第(1)个,即采用运行队列中的任务数作为描述负载的参数被证明是最有效的,即它的平均任务响应时间最短,并且已经得到广泛应用。但是,如果为了使系统信息更全面而采集了更多的参数,则往往由于增加了额外开销,却得不到所希望的性能改善。例如,采用将六个参数中的某两个进行"AND"或"OR"组合,得到的平均响应时间反而比单个参数的平均响应时间还要差一些。
传送策略
为了简单起见,在选用传送策略时,多选用阀值策略。例如,Eager等人的方法是:在判断是否要在本地处理一个任务时,无需交换计算机之间的状态信息,一旦服务队列或等待服务队列的长度大于阀值时,就传送这个任务,而且传送的是刚刚接收的任务。而进程迁移能够迁移正在执行的任务,是对这种只能传送刚刚接收的任务的一种改进。
Zhou在模拟研究七个负载平衡算法时,其传送策略都采用阀值策略。它的阀值策略基于两个阀值∶计算机的负载阀值Load和任务执行时间阀值TCPU。如果计算机的负载超过Load并且任务的执行时间超过TCPU时,就把此任务传送到其它计算机执行。
放置策略
经过总结,共有以下四种放置策略。
集中策略。每隔P秒,其中一个计算机被指定为"负载信息中心"(LIC),接受所有其它负载的变更值,并把它们汇集到一个"负载向量"中,然后把负载向量广播给所有其它的计算机。当一台计算机认为一个任务适于传送到其它计算机上执行时,它就给LIC发送一个请求,并告知当前负载的值。LIC选一台具有最短运行队列长度的计算机,并且通知任务所在的计算机把任务发送给它,同时,它把目的主机负载值增加1。
阀值策略。随机选择一台计算机,判断若把任务传送到那台计算机后,那台计算机的任务队列长度是否会超过阀值。如果不超过阀值,就传送此任务;否则,随机选择另一台计算机,并以同样方式判断,继续这样做直到找到一台合适的目的计算机,或探测次数超过一个静态值限制LP,当任务真正到达计算机以后,不管状态如何,必须处理该任务。
最短任务队列策略。随机选择LP台不同的计算机,察看每台计算机的任务队列长度,任务被传送到具有最短任务队列长度的计算机。当任务真正到达计算机,无论状态如何,目的计算机必须处理该任务。对此策略的一个简单改进时,无论何时,遇到一台队列长度为0的计算机时,不再继续探测,因为可以确定此计算机是一台可以接受的目的计算机。
保留策略。当一个任务从一台计算机离开时,该计算机检查本地负载,如果负载小于阀值T1,就探测其它计算机,并在R个负载大于T1的计算机中登记该计算机的名字,并把登记的内容保留到一个栈中。当一个任务到达一台超载的计算机时,就把这个任务传送到此台计算机栈顶的计算机上。如果一个计算机的负载低于T1,就清空栈里保留的所有计算机名。
Zhou的论文中,比较了(2)和(3)三种策略,结论是:以简单(计算不昂贵)的方式,利用少量状态信息,第(2)中方法往往获得比第(3)种方法更好的效果。第(3)中方法比较复杂,它必须用性能的改善来补偿额外花费,所以取得的效果会稍差一些[2]。
本篇是实现过程的第二个理论先导篇,作者将向我们讲述负载平衡机制的理论研究。
在计算机硬件价格下降、计算机网络拓扑发展的情况下,分布式计算机系统给用户提供了一个丰富的资源集合。人们在研究分布式系统时,就注意到了这样一个问题:在一个由网络连接起来的多计算机环境中,在某一时刻,一些计算机的负载比较重,而另外一些计算机的负载却比较轻。平衡各计算机之间的负载是任务分配与调度的一个主要目标,它能够提高整个系统的性能。
为了改善系统的性能,通过在多台计算机之间合理地分配负载,使各台计算机的负载基本均衡,这种计算能力共享的形式,通常被称为负载平衡或负载共享。一般来说,"负载平衡"要达到的目标是使各台计算机之间的负载基本均衡,而"负载共享"意味着只是简单的负载的重新分配。
负载平衡包括两种,一种是静态负载平衡,一种是动态负载平衡。只是利用系统负载的平均信息,而忽视系统当前的负载状况的方法被称为静态负载平衡。根据系统当前的负载状况来调整任务划分的方法被称为动态负载平衡。
导致负载不平衡主要是由于:
某些算法的迭代大小不是固定的,但迭代的大小在编译时却可以被求得;
某些算法的迭代大小不是固定的,并且迭代的大小依赖于被处理的数据,在编译时无法求得;
即使迭代大小是固定的,也会有许多不定因素导致计算速度的差异。
考察这三个原因,对第一种情况可在编译时估计各迭代的工作量,按照处理节点的处理能力分布迭代,这就是静态负载平衡的方法。对第二、三种情况来说,必须采用动态负载平衡的手段,在运行过程中根据各个处理节点完成任务的情况,动态地迁移任务,实现动态负载平衡。进行动态负载平衡需要考察处理节点的处理能力,它的基本依据是根据处理节点先前的处理速度预见未来的处理速度。
负载平衡算法
一个负载平衡算法都包含以下三个组成部分:
信息策略:制定任务放置策略的制定者使用的负载和任务量,以及信息分配的方式。
传送策略:基于任务和计算机负载,判断是否要把一个任务传送到其它计算机上处理。
放置策略:对于适合传送到其它计算机处理的任务,选择任务将被传送的目的计算机。
负载平衡的上述三个部分之间是以不同的方式相互作用的。放置策略利用信息策略提供的负载信息,仅当任务被传送策略判断为适于传送之后才行动。
总之,负载平衡的目标是:提供最短的平均任务响应时间;能适于变化的负载;是可靠的负载平衡机制。
信息策略
人们用来描述负载信息采用的参数有:
运行队列中的任务数;
系统调用的速率;
CPU上下文切换率;
空闲CPU时间百分比;
空闲存储器的大小(K字节);
1分钟内的平均负载。对于这些单个的负载描述参数,第(1)个,即采用运行队列中的任务数作为描述负载的参数被证明是最有效的,即它的平均任务响应时间最短,并且已经得到广泛应用。但是,如果为了使系统信息更全面而采集了更多的参数,则往往由于增加了额外开销,却得不到所希望的性能改善。例如,采用将六个参数中的某两个进行"AND"或"OR"组合,得到的平均响应时间反而比单个参数的平均响应时间还要差一些。
传送策略
为了简单起见,在选用传送策略时,多选用阀值策略。例如,Eager等人的方法是:在判断是否要在本地处理一个任务时,无需交换计算机之间的状态信息,一旦服务队列或等待服务队列的长度大于阀值时,就传送这个任务,而且传送的是刚刚接收的任务。而进程迁移能够迁移正在执行的任务,是对这种只能传送刚刚接收的任务的一种改进。
Zhou在模拟研究七个负载平衡算法时,其传送策略都采用阀值策略。它的阀值策略基于两个阀值∶计算机的负载阀值Load和任务执行时间阀值TCPU。如果计算机的负载超过Load并且任务的执行时间超过TCPU时,就把此任务传送到其它计算机执行。
放置策略
经过总结,共有以下四种放置策略。
集中策略。每隔P秒,其中一个计算机被指定为"负载信息中心"(LIC),接受所有其它负载的变更值,并把它们汇集到一个"负载向量"中,然后把负载向量广播给所有其它的计算机。当一台计算机认为一个任务适于传送到其它计算机上执行时,它就给LIC发送一个请求,并告知当前负载的值。LIC选一台具有最短运行队列长度的计算机,并且通知任务所在的计算机把任务发送给它,同时,它把目的主机负载值增加1。
阀值策略。随机选择一台计算机,判断若把任务传送到那台计算机后,那台计算机的任务队列长度是否会超过阀值。如果不超过阀值,就传送此任务;否则,随机选择另一台计算机,并以同样方式判断,继续这样做直到找到一台合适的目的计算机,或探测次数超过一个静态值限制LP,当任务真正到达计算机以后,不管状态如何,必须处理该任务。
最短任务队列策略。随机选择LP台不同的计算机,察看每台计算机的任务队列长度,任务被传送到具有最短任务队列长度的计算机。当任务真正到达计算机,无论状态如何,目的计算机必须处理该任务。对此策略的一个简单改进时,无论何时,遇到一台队列长度为0的计算机时,不再继续探测,因为可以确定此计算机是一台可以接受的目的计算机。
保留策略。当一个任务从一台计算机离开时,该计算机检查本地负载,如果负载小于阀值T1,就探测其它计算机,并在R个负载大于T1的计算机中登记该计算机的名字,并把登记的内容保留到一个栈中。当一个任务到达一台超载的计算机时,就把这个任务传送到此台计算机栈顶的计算机上。如果一个计算机的负载低于T1,就清空栈里保留的所有计算机名。
Zhou的论文中,比较了(2)和(3)三种策略,结论是:以简单(计算不昂贵)的方式,利用少量状态信息,第(2)中方法往往获得比第(3)种方法更好的效果。第(3)中方法比较复杂,它必须用性能的改善来补偿额外花费,所以取得的效果会稍差一些[2]。
算法实现
目前,常见的算法有:中心任务调度策略、梯度模型策略、发送者启动策略和接收者启动策略。
中心任务调度策略
顾名思义,中心任务调度策略就是让一个特定的处理节点担任计算任务分配器的角色,我们称之为调度节点,而把其它完成计算任务的处理节点称作计算节点。调度节点为了掌握任务分布情况,需要维护一个任务分布表。
在任务启动时,调度节点装入任务的预分布情况表,而计算节点则开始完成分配给它的计算任务。在执行过程中,计算节点按照一定的周期向调度节点提交计算任务完成情况,由调度节点根据这些信息判断处理节点的处理能力,发出任务迁移指令,控制任务从重负载节点向轻负载节点流动,同时还要随之更新在调度节点上的任务分布表。
中心任务调度的优点显而易见:调度节点掌握所有节点的处理能力和任务的分布情况,因此它可以在综合各种因素的基础上找到最佳的任务迁移方式。但是在计算节点很多时,所有计算机点都必然与中心节点通讯,必然导致严重的冲突,这会大大降低动态负载平衡的效率,甚至抵消动态负载平衡所带来的一切好处。
另外,还应该注意到,调度节点在判断是否进行任务迁移时,计算节点必须等待,这无疑又浪费了计算节点的处理能力。一种改进的方法是调度节点在收到计算节点的当前任务完成情况时,立即存储之,并把根据上次的信息做出的判断返回给计算节点以减少延迟,在空闲时再根据本次收到的信息做出判断,留到下次使用。这样就把调度节点进行任务迁移决策的时间和计算节点完成计算任务的时间重叠了起来,降低了动态负载平衡的开销。
梯度模型策略
在中心任务调度策略中,计算节点越多,冲突就越多。为了减少冲突,适应大量处理节点的需要。梯度模型策略、发送者启动策略和接收者启动策略都不设置专用的调度节点,而且每个节点只与一部分节点进行交互,以减少由负载平衡导致的冲突。
在梯度模型策略中,所有处理节点仅与直接相邻的节点进行交互,并引入两个阀值:M 1 和Mh。在运行过程中,我们将所在节点划分成三类:设一个节点的剩余任务量为t,如果t < M1则称之为轻负载节点;如果M1< t < Mh则称之为中负载节点;如果t > Mh则称之为重负载节点。另外,把从一个节点到与之最接近的轻负载节点的最短距离定义为这个节点的梯度。
在启动时,每个节点都是重负载节点,梯度都是无穷大。在计算过程中,周期性地检查其剩余负载是否大于M1。当某一节点发现自身剩余的负载小于M1时就把它的梯度设为零,随后把自身当前的梯度与相邻节点间的距离之和发送给相邻的节点。相邻的节点接收到这个新梯度,就与自身当前梯度进行比较。如果自身梯度小于等于新梯度,则不做任何事;如果自身梯度大于新梯度,则将自身梯度设置为新梯度,并向发送给它新梯度信息的节点一样传播新梯度。这样,梯度信息(实际上就是计算任务完成的情况)就会被传播开来,重负载节点就可以把它多余的负载发送给向临界点中梯度最小的节点。于是,计算任务就在梯度的引导之下从重负载节点流向轻负载节点。
可是,按照这种方式,有可能导致过多的计算任务涌向一个轻负载节点。如果轻负载节点接收了过多的新任务,就有可能重新变成中负载甚至重负载节点。一旦出现这种情况,梯度信息就不再能够正确地引导计算任务了。为此,必须使轻负载节点察看要接受的计算任务,如果接收计算任务使本节点脱离轻节点状态,就拒绝接受它。
实现过程之理论先导篇(3)
本篇是实现过程的第三个理论先导篇,作者将向我们讲述负载平衡策略,并对各种负载平衡策略作了比较。
近年来,Internet的发展步入黄金时期,网上信息交换的数量正在呈指数形式的增长。特别是,由于电子商务的蓬勃发展,人们已经预计在下一世纪,网上消费将成为日常生活的重要形式。
随着网络硬件设备的飞速进步,网络带宽的瓶颈效应日趋减弱,WEB服务器的性能问题逐渐显现出来。单一的服务器系统处理客户请求的能力有限,如何处理快速增长的客户请求,是当前研究人员关注的重要问题。从目前的研究方向看,服务器方向的研究可以归结为两个方面:
1.从实现机制上入手。主要研究Caching技术、预取技术等。这方面的研究主要从客户访问行为分析入手,研究可以缩小响应时间的方法,这些技术可以在现有服务器设备的基础上尽可能地提高系统的性能,但性能提高的程度有限。
2.从体系结构入手。将过去单一的服务器结构扩充为集群式服务器结构。这种改造可能需要增加较大的开销,但可以显著提高服务器的总体性能。
目前,常见的算法有:中心任务调度策略、梯度模型策略、发送者启动策略和接收者启动策略。
中心任务调度策略
顾名思义,中心任务调度策略就是让一个特定的处理节点担任计算任务分配器的角色,我们称之为调度节点,而把其它完成计算任务的处理节点称作计算节点。调度节点为了掌握任务分布情况,需要维护一个任务分布表。
在任务启动时,调度节点装入任务的预分布情况表,而计算节点则开始完成分配给它的计算任务。在执行过程中,计算节点按照一定的周期向调度节点提交计算任务完成情况,由调度节点根据这些信息判断处理节点的处理能力,发出任务迁移指令,控制任务从重负载节点向轻负载节点流动,同时还要随之更新在调度节点上的任务分布表。
中心任务调度的优点显而易见:调度节点掌握所有节点的处理能力和任务的分布情况,因此它可以在综合各种因素的基础上找到最佳的任务迁移方式。但是在计算节点很多时,所有计算机点都必然与中心节点通讯,必然导致严重的冲突,这会大大降低动态负载平衡的效率,甚至抵消动态负载平衡所带来的一切好处。
另外,还应该注意到,调度节点在判断是否进行任务迁移时,计算节点必须等待,这无疑又浪费了计算节点的处理能力。一种改进的方法是调度节点在收到计算节点的当前任务完成情况时,立即存储之,并把根据上次的信息做出的判断返回给计算节点以减少延迟,在空闲时再根据本次收到的信息做出判断,留到下次使用。这样就把调度节点进行任务迁移决策的时间和计算节点完成计算任务的时间重叠了起来,降低了动态负载平衡的开销。
梯度模型策略
在中心任务调度策略中,计算节点越多,冲突就越多。为了减少冲突,适应大量处理节点的需要。梯度模型策略、发送者启动策略和接收者启动策略都不设置专用的调度节点,而且每个节点只与一部分节点进行交互,以减少由负载平衡导致的冲突。
在梯度模型策略中,所有处理节点仅与直接相邻的节点进行交互,并引入两个阀值:M 1 和Mh。在运行过程中,我们将所在节点划分成三类:设一个节点的剩余任务量为t,如果t < M1则称之为轻负载节点;如果M1< t < Mh则称之为中负载节点;如果t > Mh则称之为重负载节点。另外,把从一个节点到与之最接近的轻负载节点的最短距离定义为这个节点的梯度。
在启动时,每个节点都是重负载节点,梯度都是无穷大。在计算过程中,周期性地检查其剩余负载是否大于M1。当某一节点发现自身剩余的负载小于M1时就把它的梯度设为零,随后把自身当前的梯度与相邻节点间的距离之和发送给相邻的节点。相邻的节点接收到这个新梯度,就与自身当前梯度进行比较。如果自身梯度小于等于新梯度,则不做任何事;如果自身梯度大于新梯度,则将自身梯度设置为新梯度,并向发送给它新梯度信息的节点一样传播新梯度。这样,梯度信息(实际上就是计算任务完成的情况)就会被传播开来,重负载节点就可以把它多余的负载发送给向临界点中梯度最小的节点。于是,计算任务就在梯度的引导之下从重负载节点流向轻负载节点。
可是,按照这种方式,有可能导致过多的计算任务涌向一个轻负载节点。如果轻负载节点接收了过多的新任务,就有可能重新变成中负载甚至重负载节点。一旦出现这种情况,梯度信息就不再能够正确地引导计算任务了。为此,必须使轻负载节点察看要接受的计算任务,如果接收计算任务使本节点脱离轻节点状态,就拒绝接受它。
实现过程之理论先导篇(3)
本篇是实现过程的第三个理论先导篇,作者将向我们讲述负载平衡策略,并对各种负载平衡策略作了比较。
近年来,Internet的发展步入黄金时期,网上信息交换的数量正在呈指数形式的增长。特别是,由于电子商务的蓬勃发展,人们已经预计在下一世纪,网上消费将成为日常生活的重要形式。
随着网络硬件设备的飞速进步,网络带宽的瓶颈效应日趋减弱,WEB服务器的性能问题逐渐显现出来。单一的服务器系统处理客户请求的能力有限,如何处理快速增长的客户请求,是当前研究人员关注的重要问题。从目前的研究方向看,服务器方向的研究可以归结为两个方面:
1.从实现机制上入手。主要研究Caching技术、预取技术等。这方面的研究主要从客户访问行为分析入手,研究可以缩小响应时间的方法,这些技术可以在现有服务器设备的基础上尽可能地提高系统的性能,但性能提高的程度有限。
2.从体系结构入手。将过去单一的服务器结构扩充为集群式服务器结构。这种改造可能需要增加较大的开销,但可以显著提高服务器的总体性能。
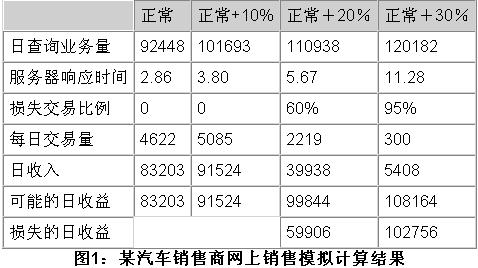
就某一商业Web站点而言,人们通常会认为,日访问人数越多,说明销售的潜力越大,潜在的购买者越多。但统计结果向我们显示的却是另一种结果。随着日访问人数的增加,销售量上升到一定程度后,反而下降。图1给出的是某汽车销售网站网上销售的模拟计算结果。注意,当网站日查询业务量为正常的120%或更高时,访问的服务时间明显增长,使得日收益反而比正常情况下降很多。
究其原因,我们不难发现,服务器的性能是导致这种现象的最根本的原因。当服务器负载接近边界时,负载的一个小小的增长都有可能使服务器陷入象死锁那样的一种境地。由此可以得出,如何优化Web服务器性能将是今后一段时间研究的一个热点。许多服务器制造商都在努力推出性能更加优良的服务器,但是单一服务器结构有一个致命的缺陷,那就是由于服务器的处理能力有限,有可能会出现死锁的情况。死锁的产生是由于新请求的到达率大于系统服务率,系统没有能力在短期内处理所有的请求,导致等待队列溢出,系统稳定状态转为不稳定状态,最后崩溃。集群服务器具有良好的可扩展性,可以随着负载的增大动态地向集群中增加服务器,从而就避免了由于处理能力不足而导致的系统崩溃。
1. 粗粒度分发策略
在集群系统中,粒度指的是负载调度和迁移的单位。集群系统中的粗粒度指的是调度和迁移的单位是服务,而细粒度指的是进程。目前,关于集群式服务器的研究主要集中在体系结构和负载平衡策略的研究上,其中负载平衡策略的研究又是体系结构研究的基础。早期的集群式服务器系统常采用Round-Robin DNS算法实现客户请求的分发。实际上是一种粗粒度的负载分配策略。
1.1 工作原理
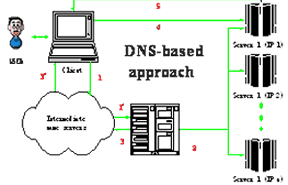
正常情况下,域名服务器将主机名映射为一个IP地址,为了改善负载平衡状况,早期的集群服务器系统采用RR-DNS(Round-Robin DNS)调度算法将一个域名映射为一组IP地址,允许客户端链接到服务器集群中的某一台服务器上,由此提供了服务器站点的伸缩性。一些可伸缩Web服务器(例如Eddie和NCSA的Scalable Web Server)采用RR-DNS实现负载平衡,一些高吞吐率的站点(Yahoo)也继续采用这种简单应用。图2为这类服务器结构的工作原理图。
1. 粗粒度分发策略
在集群系统中,粒度指的是负载调度和迁移的单位。集群系统中的粗粒度指的是调度和迁移的单位是服务,而细粒度指的是进程。目前,关于集群式服务器的研究主要集中在体系结构和负载平衡策略的研究上,其中负载平衡策略的研究又是体系结构研究的基础。早期的集群式服务器系统常采用Round-Robin DNS算法实现客户请求的分发。实际上是一种粗粒度的负载分配策略。
1.1 工作原理
正常情况下,域名服务器将主机名映射为一个IP地址,为了改善负载平衡状况,早期的集群服务器系统采用RR-DNS(Round-Robin DNS)调度算法将一个域名映射为一组IP地址,允许客户端链接到服务器集群中的某一台服务器上,由此提供了服务器站点的伸缩性。一些可伸缩Web服务器(例如Eddie和NCSA的Scalable Web Server)采用RR-DNS实现负载平衡,一些高吞吐率的站点(Yahoo)也继续采用这种简单应用。图2为这类服务器结构的工作原理图。

图 2 基于DNS机制的集群服务器结构
RR-DNS在解析域名时,附加一个生存期(TTL:Time-To-Live),这样一个请求生成后TTL时间内没有获得应答信息,可以向RR-DNS获取不同的IP地址。
1.2 工作流程
1.客户发出地址请求(URL)
地址请求报文到达DNS
2.DNS选择服务器IP地址和TTL
3.地址映象(URL->ADDRESS 1)
地址映象(URL->ADDRESS 1)
4.客户向服务器1发出文档请求
5.服务器1响应客户的文档请求
1.3 存在缺陷
在一个TTL时期内,多个域名请求将被映射到相同的IP地址,这样大量的客户端请求可能出现在同一服务器上,导致明显的负载失衡。如果TTL很小,又会明显增加域名解析的网络负载。
另一个相关问题是由于客户端缓存域名-IP地址解析结果,客户端可以在未来的任意时刻发送请求,导致服务器的负载无法得到控制,出现服务器负载失衡。
1.4 相关算法研究
为解决请求的负载分布均衡问题,研究者对RR-DNS算法进行了多种改进,这些改进依据TTL的设定形式可分为TTL恒定算法和自适应TTL算法。
TTL恒定算法
TTL恒定算法根据用户使用系统状态信息的情况又可分为系统无状态算法、基于服务器状态算法、基于客户状态算法和基于服务器/客户状态算法。
1.SSL:系统无状态算法system-stateless algorithm
系统无状态算法指DNS服务器按固定时间间隔将客户请求分发到不同服务器上。例如时刻的客户接受服务器k1的服务,时刻的客户接受服务器k2的服务,式中的为TTL值。客户获取服务器地址后,将地址缓存在客户端,然后根据需要,向服务器发请求。
使用系统无状态算法,DNS只能控制部分请求的流向,由于不考虑服务器的容量和可用性,以及客户请求到达的不确定性,导致服务器超载或将请求发送到不可用服务器上,此算法性能很差,没有实用价值。
2.SSB:基于服务器状态算法Server-state-based algorithm
获取服务器状态的目的是为了选择可用性更高的服务器处理客户请求,防止服务器阻塞或服务失败。服务器状态算法需要使用简单的服务器侦听机制(例如心跳协议等)对服务器状态进行定时跟踪。当客户请求到达时,将负载最轻的服务器地址映射给客户端。SUN-SCALR在实现上就是采用这种机制。
3.CSB:基于客户状态算法Client-state-based algorithm
来自客户端的信息可归结为客户访问的平均负载状况和客户分布情况。如果不考虑客户的优先级高低,CSB算法使用HLW(hidden load weight)参量描述新客户的到达率(TTL周期内,访问服务器的新客户数量),根据新客户到达率,进行服务器分配,这类算法的典型代表是MRRP(multitier round-robin policy)。
另外,Cisco的Distributed Director在实现上也采用CSB策略,Distributed Director在服务器集群中充当主域名服务器,根据客户-服务器的拓扑距离和新客户到达率,选择最适合的服务器分发给客户。
4.SCSB:基于服务器/客户状态的算法server and client state based algorithm
在DNS算法中,同时使用服务器状态和客户状态信息时,获得的性能往往是最高的。例如Distributed Director的DNS算法以服务器可用信息和客户的距离信息为指标分配处理服务器。当节点服务器超载,服务器发送异步警报反馈信息给DNS控制器,控制器将此服务器从可用服务器表中剔除,根据客户状态信息选择最有利的服务器处理客户请求。使用此算法需要对服务器状态进行动态分析和预测。
5.WRR:带有权重的RR算法 Weight Round-Robin algorithm
根据各台实际服务器的处理能力给它们分配不同的权重,使具有相同权重的服务器获得链接的概率相同,高权重的服务器获得链接的概率比低权重服务器获得链接的概率大。
自适应TTL算法[20]
为平衡多服务器节点的负载,特别是异构服务器的负载,人们提出了自适应的TTL算法。这类算法使用基于服务器/客户状态DNS策略选择节点服务器,并动态调整TTL值。在异构服务器集群中,根据各服务器容量不同,设置的TTL值也不完全相同,由此控制因负载不对称造成的超载问题。
自适应TTL算法使用两步表决机制:首先DNS选择服务器的方法和基于客户状态算法相似;第二步,DNS根据负载分布情况、服务器处理能力和服务器的繁忙程度选择合适的TTL值,服务器越忙,设定的TTL值越小。
另外,自适应TTL算法的可扩展性很强,算法实现中的数据都可以动态获得。使用自适应TTL算法可以使服务器集群比较容易地从局域网拓展到广域网。
1.5 DNS算法比较
由于客户端和中间域名服务器缓存URL-IP地址映射,使用服务器状态信息的DNS算法不能保证负载平衡[15],每个地址缓存都有可能引发大量的客户请求阻塞集群中的某个服务器节点。因此,合理地预测客户请求的到达率对于选择服务器更加有效。
使用客户到达率信息和服务器监听的调度算法可以获得更高可用性的服务器。但是这种算法明显不适于异构型集群服务器。
为平衡分布系统的请求负载,自适应TTL算法是最可靠、有效的。但是,这种算法忽略了客户-服务器距离的重要性。
细粒度分发策略
为实现客户请求的集中调度和完全路由控制,采用细粒度负载分配策略的服务器结构中必须包含一个路由器节点──平衡器(可能是一个硬件路由器或集群服务器中配置专用软件的节点)接收发向Web站点的所有请求,根据某种负载平衡算法将请求转发到不同的服务器节点上。
与基于DNS的体系结构不同的是,平衡器采用单一的、虚拟IP地址IP-SVA(single virtual IP adress),这个IP地址是众所周知的一个IP地址,而节点服务器的实际地址对用户是透明的。由于此机制是在URL层进行请求的处理,Web页中包含的多个目标,可以由集群中的不同节点提供,这样提供了比RR-DNS更细粒度的控制策略。
| 自由广告区 |
| 分类导航 |
| 邮件新闻资讯: IT业界 | 邮件服务器 | 邮件趣闻 | 移动电邮 电子邮箱 | 反垃圾邮件|邮件客户端|网络安全 行业数据 | 邮件人物 | 网站公告 | 行业法规 网络技术: 邮件原理 | 网络协议 | 网络管理 | 传输介质 线路接入 | 路由接口 | 邮件存储 | 华为3Com CISCO技术 | 网络与服务器硬件 操作系统: Windows 9X | Linux&Uinx | Windows NT Windows Vista | FreeBSD | 其它操作系统 邮件服务器: 程序与开发 | Exchange | Qmail | Postfix Sendmail | MDaemon | Domino | Foxmail KerioMail | JavaMail | Winwebmail |James Merak&VisNetic | CMailServer | WinMail 金笛邮件系统 | 其它 | 反垃圾邮件: 综述| 客户端反垃圾邮件|服务器端反垃圾邮件 邮件客户端软件: Outlook | Foxmail | DreamMail| KooMail The bat | 雷鸟 | Eudora |Becky! |Pegasus IncrediMail |其它 电子邮箱: 个人邮箱 | 企业邮箱 |Gmail 移动电子邮件:服务器 | 客户端 | 技术前沿 邮件网络安全: 软件漏洞 | 安全知识 | 病毒公告 |防火墙 攻防技术 | 病毒查杀| ISA | 数字签名 邮件营销: Email营销 | 网络营销 | 营销技巧 |营销案例 邮件人才:招聘 | 职场 | 培训 | 指南 | 职场 解决方案: 邮件系统|反垃圾邮件 |安全 |移动电邮 |招标 产品评测: 邮件系统 |反垃圾邮件 |邮箱 |安全 |客户端 |