Microsoft 的邮件处理操作
本页内容
| 执行概要 | |
| 介绍 | |
| 背景 | |
| 最佳实践 | |
| 结论 |
执行概要
基于 Microsoft Exchange Server 2003 早期使用者 —— Microsoft 内部 IT 部门(属于操作技术部门 [Operations and Technology Group,OTG] 的一部分)的经验,本白皮书描述了 Microsoft Exchange Server 2003 日常操作中总结的最佳实践。本文着重阐述了 Microsoft Exchange Server 2003 与 Windows Server 2003 和 Microsoft Office 2003 Editions 之间新的依存关系。并详细描述了 OTG “早期使用者”帮助客户规划从 Exchange 2000 Server 升级至 Exchange Server 2003 的经验。
本文提及了还可应用到 Exchange 早期版本的最佳实践。而 Microsoft Office 2003 Editions 的桌面部署,升级 Microsoft Exchange Server 5.5,以及客户端问题(如 Microsoft Outlook 2003 Exchange 缓存模式部署)在本文中则未有包含。
本白皮书是为企业技术决策制定者和希望利用 Exchange Server 2003 增强功能的操作人员而编写的。本文假定读者对 Exchange 的设计、部署和操作均有较深的了解。
Microsoft 共享此信息,以帮助其客户在他们自己的环境中操作 Exchange Server 2003。OTG 的推荐和设计细节是基于早期使用者的经验和 Microsoft IT 环境。本白皮书不用作程序指南。每个企业环境都是由其特殊的条件构成,因此,它们都需要调整所学到的程序和经验以适应其具体需求。
注: 出于安全考虑,本文中使用的目录森林、域、内部资源及组织均不代表 Microsoft 内部的真实资源名称,仅用于举例说明。
介绍
当 Microsoft 软件在 Microsoft 内部部署运行后,客户经常向 Microsoft 操作技术组 (OTG)咨询有关部署方法和积累的经验。本文为 Microsoft 客户揭开了 OTG 如何在 Microsoft 内部操作 Microsoft Exchange Server 2003的内幕。
以下章节描述了Microsoft 的内部 IT 环境,着重介绍了邮件处理。本文第二部分中,最佳实践和积累的经验都是基于 Microsoft 业务需求与其环境的相互影响。在阅读其他部分之前首先阅读“背景”部分,将有助于您了解这些建议对您的适用性。
Microsoft 操作框架和服务管理功能术语
为了帮助企业专业人员有效的管理 IT 操作,Microsoft 开发了 Microsoft 操作框架 (Microsoft Operations Framework, MOF)。该框架是有关最佳实践、原则和模式的文档集,为专业人员提供了技术指南。以下 MOF 的指南,将有助于您在使用 Microsoft 产品时,获得关键任务生产系统的可靠性、可用性、可支持性和可管理性。获得更多有关信息,请访问 http://www.microsoft.com/china/technet/itsolutions/techguide/mof/default.mspx.
每家公司描述 IT 操作任务的术语不尽相同。一家公司所说的“防病毒与垃圾邮件管理” SMF 可能被另一个公司描述为“容量与可用性管理”。本白皮书使用 MOF 服务管理功能 (Service Management Function,SMF) 术语。
运营技术部门
OTG 负责的工作范围很广泛,包括公司内部网络、通信系统、企业服务器以及一系列商业应用程序的运行。OTG 提供的 IT 环境融合了服务、应用程序以及基础结构,并帮助为全球 400 多个地区,近 57000 名职工、合同工、商家和见习人员提供可用性、隐私和安全性。
除了在内部提供全球 IT 服务之外,OTG 还负责在 Microsoft 企业产品发布给客户之前,对生产过程中的产品进行测试,以确保这些产品可以通过伸缩调整来满足其他大企业业务的需求。这个过程在内部称之为“Eating our own dogfood(吃窝边草)”。通过如本文这样的白皮书,OTG 的客户服务伸展到共享早期使用者的经验、最佳实践和积累的经验。
与其他企业 IT 组织相似,OTG 的运营目标集中在获得可用性、性能、灵活性与成本之间的适当平衡。唯一不同在于,OTG 经常在Microsoft 解决方案发布给公众以前,尽可能使用这些方案。
为了达到这些目标,模型企业(Model Enterprise)策略基于以下原则:
| • | 最大限度提高在中央(不是在设备上)运行的管理任务数量。 |
| • | 减少数据中心数目,以及基础架构和应用程序服务器的数目。 |
| • | 使全球的基础结构与设备标准化。 |
背景
OTG 组织与结构
过去,Microsoft 约有 2500 名员工的 IT 组织在构建公司 IT 基础架构时,一直在集中式系统与分散联合式模型之间不断变换。为了创建一个更加稳定的基础架构,自本文编写起,OTG 已将每个系统最有效的方面综合起来。
集中对于有效管理基础架构(该基础架构必须跨组织和地理边界无缝地运行)的关键元素至关重要。必须跨组织和地理边界运行的系统包括网络、电话、 消息与协作服务,备份与还原服务、网络操作和命令中心。集中运行这些系统也会降低成本。在服务器与桌面上的硬件与软件标准化对于控制该模式下的技术支持成本十分关键。
策略性的开端通常都是分散的,如区域 IT 问题、早期使用者的努力以及支持产品开发与测试的部署方案。
桌面支持模式 (Helpdesk)
Microsoft 内部技术支持组织是一个基于呼叫中心模式的集中式组织。 呼叫中心每起事故的成本大约是技术员做一次现场查看成本的 33%。有近 200 名员工在 3 个区域呼叫中心工作,另外有 300 名现场技术人员负责全球的用户群(包括 57000 多名职员、合同工和商家)。Helpdesk 平均每月接入来自全球约 50000 个免费电话。截至本白皮书编写时,10%以上的电话都是通过使用 Windows XP 中远程协助 (Remote Assistance) 来解决的,减少了现场访问的成本。截至本白皮书编写时,约有75%的事故都按照“先联系”的方法解决。
网络基础架构
Microsoft 内部网络,即熟知的 corpnet,遵循的逻辑设计与 Microsoft 系统体系结构企业数据中心 (Microsoft Systems Architecture (MSA) Enterprise Data Center) 推荐的逻辑设计类似。通过使用 Microsoft 及其合作伙伴的技术,MSA 规定性的结构指南为创建地理分布式企业数据中心架构提供了蓝图和向导。请访问 http://www.microsoft.com/solutions/msa/evaluation/overview/edc/default.asp获取有关 MSA 的进一步信息。
虽然在 Microsoft 公司网站上运行了多种用于进行开发和测试的网络协议,但是该运行环境主要是基于传输控制协议/Internet协议 (TCP/IP)。本白皮书中,Exchange Server 2003 邮箱服务器流量、Outlook 2003 消息与协作客户端服务器流量都仅为远程过程调用(RPC)。Exchange Server 2003 还提供了访问邮箱服务器的其他方法,如”通过 Internet 上的 Outlook “(需要 Windows Server 2003、Exchange Server 2003、Windows XP Professional SP1 和Outlook 2003),以及用于 Outlook 移动访问 (Outlook Mobile Access, OMA) 的 HTTP 和 Outlook Web Access 的 Exchange Server 2003 版本中所使用的 HTTP。 Microsoft 所有传入信息处理的连接都是 HTTP。本白皮书中不包含这些协议的日常操作问题。
为了提高安全性,远程用户访问 corpnet (RAS/VPN) 必须使用智能卡双因子身份验证。
高层概念设计如图 1 所示。
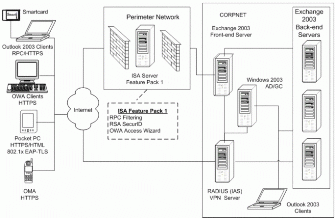
该网络的设计是基于多域路由模式。它分为 4 个区域网络,每个区域网都起到单个开放式最短路径优先 (Open Shortest Path First) 路由和寻址域的作用。每个区域网络由中枢区域和多区域组成,以保证每个区域网络的可伸缩性。外部边界网关协议 (External Border Gateway Protocol) 用于交换区域网间的路由,以确保网络作为一个整体的可伸缩性。
Puget Sound 城域网 (Metropolitan Area Network,MAN) 支持在全球企业网路上大量数据的流量,为大楼与本地区主要数据中心之间提供了 gigabit 速率的网络连接。该总部区域由 70 栋独立的大楼和两个拥有网络基础架构的数据中心构成,提供了与公司资源、开发人员实验室网络以及 Internet 的访问。
该网络依赖于 Gigabit Ethernet 和同步光纤网 (Synchronous Optical Network) 上的数据包 (Packet)。在 MAN 中,通过利用波分复用 (Wave Division Multiplexing) 技术,在单个物理连接中提供多线路,从而实现有限光纤资源的有效利用。
可用网络带宽对于应用程序(如 Exchange Server 2003 和站点间的连接)非常重要。从 2003 年 6 月起,网络已经发展到包含:
| • | 2000 多个路由器和超过 275 台的ATM交换机
| ||||||||
| • | 世界上最大的无线 LAN (802.1x EAP-TLS)
| ||||||||
| • | 全球有 3 个企业数据中心和 19 个区域数据中心
| ||||||||
| • | 物理网络的所有部分都是从单一物理空间来监控,这个物理空间同时容纳了以下 OTG 监控小组:
|
目录森林 与域结构
正如迁移到 Windows 2000 Active Directory 的大多数组织,OTG 最初部署了一个 Active Directory 设计,它能与现有 Windows NT 4.0 域体系结构共存,并且能够从该体系结构轻松升级的。该设计在 Windows Server 2003 升级中没有较大的变化,它是基于单一 Active Directory 产品目录林 (corpnet.microsoft.com) 。
该 corpnet Windows 2003 目录林是 OTG 控制的企业域用户账户、组织以及企业资源的主要容器。目录林的根是 corpnet.microsoft.com 域。该域是仅包含有限数量的企业范围资源与管理帐户的顶层容器。在 microsoft.com 之前添加了前缀 (DC=corpnet),以将企业网与 Internet 命名空间区分开来。
本白皮书详细介绍的操作最佳实践涉及到主要企业产品目录林。另外三个产品级目录林用于支持产品开发,并且用于在企业目录林部署之前,推出新的功能。此外,还存在一个目录林,即外部网,它用于供合作伙伴访问企业资源。该设计中的多个目录林使 OTG 可以集中管理产品开发目录林用户和组,以及企业网资源,而又使开发环境不受产品开发环境必需的 Active Directory 架构变更的影响。此结构不需要做大的改动就可以迁移至 Windows Server 2003 目录林模式。
邮件处理基础架构
OTG 负责维护全球 150000 多台计算机。至本白皮书编写时为止,Microsoft 的邮件处理环境已由 200 多台服务器组成,包括分布全球 75 个地方的 190 台 Exchange 2003 服务器(其中 113 台是活动邮箱服务器)和其他跨目录林测试环境中的服务器。该环境支持:
| • | 平均每天 6000000 封邮件的全球邮件流量,同时平均每天还有 2500000 封 Internet 电子邮件。 |
| • | 每个用户邮箱大小为 200 MB,由平均每台 20 个数据库的服务器支持,在新的群集部署中,最大数据库大小为 50 GB。 |
| • | 99.9% 的全球服务可用性,能获得群集服务器上 99.99% 的服务。 |
| • | 95% 全球邮件递送的时间都不超过 90 秒。 |
| • | 每个数据库备份和还原操作服务水平协议 (Service Level Agreement,SLA) 的时间不超过 1 小时。 |
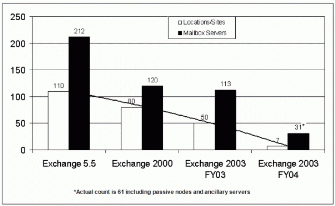
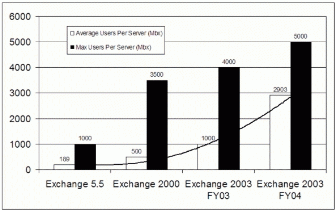
日常操作任务可以通过设计阶段所做的选择来安排和决定。例如,从版本 5.5 开始,对于Exchange 每个版本的初次发行,OTG 都通过增加每台服务器的邮箱数量,并同时减少站点或位置的数量来改进日常邮件处理操作。图 2 和 图 3 显示了历史趋势,包括下一财年的预测数据。
单服务器的可管理性角色
OTG 策略将基础架构服务器(如邮件处理服务器)部署为专门角色,以进行有效管理。表 1 显示了如何分布邮件处理服务器。
表 1 邮件处理服务器角色分布
| 服务器角色 | 运行 Exchange Server 2003 的服务器数量 |
邮箱 | 113 |
公用文件夹 | 20 |
邮件处理中心 | 12 |
Internet 网关 | 22 |
出站传真 | 3 |
语音邮件 | 2 |
* 前端服务器与 Exchange Server 2003 部署进行了合并,因为 以往包含在 Mobile Information Server 2002 中的技术 已经添加到了 Exchange Server 2003 中。为了提高系统的可用性,每台 Exchange Server 2003 前端服务器部署站点都被配置为带有一对负载平衡服务器。
业务持续性和灾难恢复限制
Microsoft 邮箱服务器基于业务持续性限制进行设计和管理。因为 Exchange 5.5 被限制为单一信息存储,所以从备份磁带进行还原的应用局限迫使每个邮箱服务器仅有 1000 个邮箱。
从 Exchange 2000 Server 开始,对多存储组和数据库的支持(达到每台服务器 20 个数据库)使 OTG 可以在每台服务器上部署更多的邮箱,并同时维护目标恢复 SLA。
通过将 Exchange Server 2003 和 Windows Server 2003 中的软件增强与高级服务器硬件功能(如 SAN 和超线程 CPU)进行结合,OTG 能够实施更大的服务器,每台服务器可以托管 5000 个 200 MB 容量的邮箱。此外,硬件改进(如更快的总线速度)和软件增强(如 Exchange Server 2003 新增的 Recovery Storage Group 功能)使 OGT 可以达到或超越“1 小时”的 SLA 需求。
客户端配置文件
理解环境中的使用模式对设计、构建和测试 Exchange 基础架构至关重要。
普通的Microsoft 职员使用 3 台与 Exchange 同步的计算机。此外,这些职员中的相当一部分还携带与 Exchange 同步的 Pocket PC 和 Smartphone 设备。截止本白皮书编写时,OTG 企业标准邮件处理客户端是在 Windows XP Professional Service Pack 1 上的 Exchange 缓冲模式中运行的 Outlook 2003。
OTG 现在不再使用普通的用户配置文件来规划服务器设计,而是研究实际的使用模式。例如,OTG 测量的一段时间内服务器并发约为 80%,这就意味着每天大部分时间中,该服务器上 80% 的可能用户在使用该服务器。然而,该使用模式是相当均匀分布的。约 25% 的用户每天检查电子邮件的时间不到 1 小时,约 29% 的用户使用时间在 8 个小时以上,如表 2 所示。
表 2 Microsoft 企业用户信息配置文件–Exchange 2003
| 每天发送的邮件 | 用户百分比 |
1–10 | 72.15% |
26–50 | 18.01% |
50–100 | 8.58% |
约 90% 的 Microsoft 用户每天发送 50 封电子邮件或更少,平均发给 5 个接收人。约 25% 的用户每天接收 100 封以上的非垃圾电子邮件(垃圾过滤器删除了大量传入的邮件,有时高达 75%)。表 3 显示了其分布。
表 3 Microsoft 企业用户邮件处理配置文件 —— Exchange 2003
| 每天接收的邮件 | 用户百分比 |
1–10 | 25% |
26–50 | 18% |
51–75 | 17% |
76–100 | 14% |
101–500 | 26% |
路由组和管理组结构
在 Exchange 2000 Server 以前所有的 Exchange 部署中,OTG 将 Exchange 服务器分组到基于网络拓扑结构的站点。Windows 2000 上的 Exchange 2000 部署使 OTG 能够将服务器安装于独立于管理组成员的路由组中,并在保留大型管理组优势的情况下优化路由拓扑结构。
目录复制现在是一种 Active Directory 功能,并且是一个操作系统级的问题,该问题对 Exchange 部署不再至关重要。因为路由组和管理组不必相同(如 Exchange 5.5 和早期版本中的情况),所以 OTG 邮件处理操作人员可以随意将 Exchange 2003 服务器放入与其管理和操作结构匹配的组中,以及符合 WAN 拓扑结构的路由组中。这种安排将目录复制问题交给了另一个专门致力于此方面的 OTG 小组解决。至本文编写时为止,为了适应测试、开发以及产品开发组的需求,OTG 维护了 31 个 Exchange Server 2003 路由组和 11 个管理组。
数据中心操作
IT 环境
Microsoft 使用的 3 个主要企业数据中心分别位于华盛顿的雷蒙德、爱尔兰的都柏林,以及日本的长府。此外,还有 16 个区域数据中心和近 400 个全球业务点。数据中心操作 (Data Center Operations,OPS) 组向 Microsoft 数据中心管理服务器的所有者提供 3 种服务级别。表 4 描述了这些服务级别。
表 4 服务级别
| 服务级别 | 服务器 | 说明 |
1 | ~700 | 电源、空调装置和网络接头 (Network Tap) |
2 | ~2,000 | 电源、空调装置和网络接头 数据备份支持。 响应支持。在服务器非正常运行时,服务器所有者呼叫 Help Desk,在OPS 收到通知后采取措施。 |
3(完全管理的) 关键业务 | ~6,000 | 电源、冷却装置和网络接头 数据备份支持。 服务器硬件和操作系统的前瞻支持,包括通过 MOM 的完全前瞻监控和对补丁兼容性的完全监控。 |
完全管理对核心基础架构(如文件和打印服务器、代理服务器、远程访问服务器以及运行 Active Directory、DNS 和 WINS 的服务器)的有效日常操作至关重要。服务级别 2 常被实验室服务器选用。不管选择了哪种服务级别,每个服务器所有者都负责在应用层或更高层管理并维护服务器。例如,服务器所有者负责管理用户权限。
在 Microsoft,服务器所有者必须使用许可的服务器软件版本和最新补丁。服务器所有者还必须使用由许可厂商根据企业标准规格生产的硬件。此标准确保 OPS 可以通过集中管理这些服务器来控制成本。
逐级提交的层次结构
当在 Microsoft 识别到一个完全管理服务器的问题时,可以按照以下顺序逐级提交:
层级 1,Helpdesk。 大部分邮箱服务器问题都是在层级 2 监测到的。然而,如果服务器所有者或应用程序用户识别出了该问题,他(或她)就可以联系 Helpdesk。较小的区域邮箱服务器实行集中式监控,操作系统和 Exchange 服务项目也实行集中式管理。区域邮箱服务器的硬件问题在本地进行处理。区域技术支持人员执行任何需要的手动服务器操作,并且使用用户团体的母语为他们提供一线支持。
层级 2, 数据中心操作 (OPS)。 OPS 使用 Microsoft Operations Manager (MOM) 警告来前瞻性地监控服务器,以防出现问题,这就使许多问题可以避开 Helpdesk。然而,如果服务器所有者发现了问题,并且与 Helpdesk 取得了联系,Helpdesk 再与数据中心 OPS 或消息操作小组联系,以采取进一步措施。收到警告的 OPS 使用内部开发的疑难解答指南 (Troubleshooting Guide,TSG) 处理了(花费了预定义的时间,如 15 分钟)关于问题的初始回复。OPS 还启动了Microsoft 内部开发的通知系统中的故障通知功能。该系统将通知跟踪系统与几个知识管理功能(如产品组知识库、TSG 和其他内部资源)进行了集成。该通知系统用于管理从发现、记录到调查、诊断和最终解决事故的全生存周期。
当问题很常见且其解决方案为人熟知并且易于实施时,即可为它创建 TSG。如果 OPS 不能解决该问题,他们就增强 TSG 中的每项说明,以调查和分析根本原因。TSG 链接到自定义通知应用程序中的警告。
注:在 Microsoft查看技术摘要 “监控消息”的更多信息,请访问 http://www.microsoft.com/technet/itsolutions/msit/operations/monittsb.mspx
在 Microsoft 查看白皮书“监控企业服务器”的更多信息,请访问 http://www.microsoft.com/technet/itsolutions/msit/operations/entserv.mspx
层级 3,基础架构支持 (Infrastructure Support,IS) 和高级诊断及调试 (Advanced Diagnostics and Debug,ADD) 小组。 根据问题的性质,OPS 可以联系 IS 或 ADD。IS 提供核心基础架构服务的“端到端”措施和管理。ADD 专门调试 Windows 操作系统问题,并直接与产品开发组进行交流。
层级 4,系统设计。 如果问题涉及到要修改 IT 体系结构、硬件标准或软件标准,IS 则会联系体系结构工程部。
多主 (Multi-homed) MOM 基础架构
Microsoft 用于监控 Exchange Server 2003 的 MOM 基础架构是多主的。这使不同的团队都可以使用该数据。例如,邮件处理操作小组对 Exchange 方面的活动、性能数据、以及阈值警告(如 RPC 平均延迟)感兴趣。而 OPS 小组则对不同的信息,如硬件、操作系统或磁盘子系统相关的潜在问题等感兴趣。
每个团队都有它自己的一套规则和配置组合。如果监控的条件发生,就产生一个事件,然后 MOM 发送一条警告自动通知相关的小组。
自定义的数据转换服务 (Data Transformation Services) 工作每天运行,获取 Exchange 的关键性能数据,以进行长期趋势分析。例如,在进行存档以前,所有的样例数据将保留 8 天。事件也保留 8 天。解决的警告保留 4 天。将 Exchange 服务器上 6 个月的可用数据保留在 SQL Server 2000 数据库中,用以进行长期趋势分析。多主体系结构如图 4 所示。
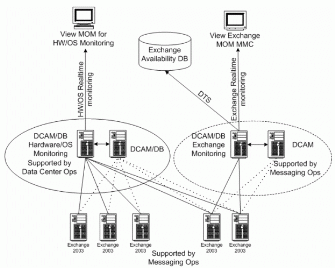
在 OTG 管理的 190 台 Exchange 服务器中,MOM 平均每天产生 200 个警告,它们是从近 42000 个事件和 6 百万个性能数据样例中筛选出来的。这 200 个警告平均产生约 66 个故障通知。自从 MOM 基础架构进行了标准化以来,警告与通知的比率已从过去的 35:1 下降至 3:1。
最佳实践
Microsoft 操作框架 (Microsoft Operations Framework,MOF) 识别对大多数服务解决方案通用的服务管理功能。每个 SMF 提供一致的策略、过程、标准、以及可以应用到 IT 环境中整套服务解决方案的最佳实践。为了便于导航,以下章节虽然划分了具体的 SMF 标题,但所有 SMF 之间都是相互关联与依存的。
迁移
Exchange 2000 和 Exchange 2003 处理目录服务的方式与 Exchange 5.5 有很大差异。在 1999 年,Microsoft 已完全从 Exchange Server 5.5 迁移到 Exchange 2000 Server。本白皮书中的最佳实践是基于 Microsoft 的内部经验,它涵盖了从 Exchange 2000 Server 进行迁移的内容,但不包括从 Exchange Server 5.5 进行迁移的情况。
规划服务器合并
如果您要规划一个与部署同步的服务器合并项目,OTG 建议您的合并计划采用以下 9 个步骤。
1. 评估当前的基础架构
| • | 确定服务器的容量和使用率。CPU 使用范围?每台服务器容纳多少个用户邮箱?存在什么并发? |
| • | 记录现有的支持和管理过程。 |
| • | 列出服务器基础架构清单。 |
| • | 确定管理和维护基础架构的成本。 |
2. 确立目标
| • | 确定项目的最高业务和技术优先级。 |
| • | 在优先项之间做出权衡,包括高可用性、成本缩减和基础架构的灵活性。 |
| • | 确定新环境的计划容量目标。 |
| • | 确定管理和维护合并后基础架构的成本目标。 |
| • | 绘制出合并计划的进度安排和预算图。 |
3. 设计新环境
| • | 研究硬件和软件选项。 |
| • | 基于容量和增长需求选择基础架构。 |
| • | 设计故障切换和冗余。 |
4. 规划迁移过程
| • | 评估每种合并方法将带来的业务影响。 |
| • | 在合并期间或之后确定组织角色和责任。 |
| • | 在实施之前全面评估计划、风险、预算和预期的结果。 |
5. 构建、测试并实施一个新的试验环境
| • | 确定并购买所必需的硬件和软件。 |
| • | 记录网络和基础架构设计。 |
| • | 针对可能出现的技术限制和风险进行规划。 |
| • | 构建并测试合并环境。 |
6. 记录并测试迁移用户和数据的规划。
| • | 编写将用户和数据迁移到新环境的过程。 | ||||||||
| • | 建立详细的部署进度安排,包括意外事故计划。 | ||||||||
| • | 制定过程的标准。例如:
|
7. 实施新的开发环境
| • | 在新的合并开发环境中部署应用程序、实用程序和工具。 |
| • | 开发并记录合并以后的维护和管理过程。 |
8. 将用户和数据迁移到合并的环境
| • | 确保在迁移前已准备好相应的备份和意外事故计划。 |
| • | 根据详细的进度安排完成迁移。 |
| • | 测试合并的环境,包括用户和数据。 |
| • | 转换至新的开发环境。 |
9. 评估和检查
| • | 评估合并项目的结果,包括成本和维护过程。 |
| • | 定期重新评估合并。 |
| • | 优化环境。 |
要了解合并最佳实践的更多信息,请访问 http://www.microsoft.com/windowsserversystem/articles/consolidation/default.mspx.
图 5 中的示例显示了一棵高层决策树,用于指导关于邮箱服务器合并的决策。
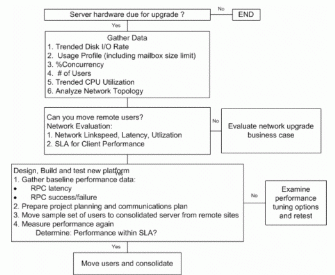
设计服务器合并
为了支持正在进行的服务器和位置的合并,服务器设计应该考虑以下 3 个主要因素:网络速度 (LAN/WAN)、成本以及备份和还原 SLA。
网络考虑因素
客户端和服务器之间的网络性能可以帮助您判断现有网络是否满足合并用户。在进行分析以后,您可以决定网络改进的预算,以支持用户的合并。如果网络改进的花费非常高,您可以决定保留远程站点中的本地服务器。
考虑网络拓扑结构与性能
因为合并可能会为网络带来其他的压力,所以应该考虑到网络拓扑结构、带宽、延迟以及性能等方面的因素。
在规划消息系统时,在指定时间内可以通过网络进行传输的数据总量是需要考虑一个关键因素。其数据传输量是由带宽和延迟综合决定的。这两个因素综合决定了在特定时间内可以通过网络进行传输的数据总量。这两个因子的乘积直接影响到用户对完成每项交易所需时间的估计。
在评估网络链接时,带宽和延迟都需要进行评估,需要认识到有些网络连接类型虽然可以最大化带宽,但它们可能会增加延迟。例如,卫星连接也许可以提供高带宽,但相对于地面连接(如帧中继服务和拔号 ISDN 服务),它可能要需要更长的延迟。
对于 Exchange Server 2003 而言,推荐用于连接到远程办公室的最小带宽为 56 Kbps。在映射站点位置和连接时,需要确定网络连接的类型和速度,以及由于站点间距离导致的延迟总量的因素。建议您将网络升级作为项目的一部分。
禁用网络适配器上的自动协商 (Auto-Negotiation) 功能
确保任何网络适配器上都没有启用自动协商功能。强制服务器和交换机的连接速度和连接类型。默认情况下,大多数网卡都在安装时自动协商其连接速度和连接类型。这会导某些性能减退。因此,为了最大化连接功能,将服务器系统上的连接速度和连接类型强制为 100 MB 全双工。
在系统投入开发以前,通过测量线缆上的字节和输出队列长度评估网卡的执行情况。 一个 100 MB 的适配器每秒具有 7 MB 的持续吞吐量,而 1 GB 的适配器每秒则支持 30 - 40 MB 的吞吐量。如果各项都快达到了相应的极限,同时输出队列长度开始大幅增加,您就必须解决这个问题。
对比评估 Gigabit 与 100 MB 的以太网
Gigabit 以太网用于 OTG Exchange 2000 Server 的设计,以最大化备份过程中独立 Exchange 服务器上的网络吞吐量。这些服务器通常每台容纳 200 - 300 GB 的数据。在 OTG 开始使用群集以后,在进行磁盘到磁带的备份时不再完全依赖网络吞吐量。OTG 现在在每个群集中使用备用节点,通过直接光纤连接将备份数据传送到磁带库中。
在通过使用带有光纤连接库的群集消除对超快速网络吞吐量的依赖以后,OTG 通过使用 100 Mbps 以太网网络适配器代替 Gigabit 以太网网络适配器,简化了服务器的维护工作,并且节省了成本。这些适配器仍然提供许多网络性能功能,完全满足 Exchange 服务器的需求,同时用于维护的开销更低。
成本因素
Exchange Server 2003、Windows Server 2003、Outlook 2003 客户端中的性能增强,以及改进的硬件(处理器,SANS)使 OTG 每台服务器可以比以前托管更多的用户。
| • | 超线程 CPU 可以降低 CPU 许可成本。 |
| • | 与操作并维护多个小型邮箱服务器和存储阵列相比,SAN 存储解决方案可以降低长期的拥有总成本。 |
| • | 在 Exchange 中,事务日志可以被连续访问,并且数据库可以进行随机访问。 为了与常规的存储最佳实践一致,应该将事务日志(连续 I/O)从数据库(随机 I/O)中分离出来,以最大化其性能并增加容错能力。特别要注意的是,应该将每组事务日志移到其自己的阵列中,使它与数据库和其他 Exchange 数据(如 SMTP 队列)分离开来。下面的这些应用将影响解决方案中使用的磁盘总数,并会影响部署成本。 |
磁盘 I/O 因素
磁盘问题是大型 Exchange 部署中的常见瓶颈。成功的消息存储性能依赖于关键的指示器:响应时间、吞吐量以及可预见行为。Exchange 客户端使用配置文件是在设计合适的磁盘子系统时要考虑的主要因素,这也使得该行为具有可预见性。一旦具有了可预见性,管理存储区操作就可以更集中于功能管理方面,而不是忙于中断/补救任务。
您可以使用 Microsoft Exchange 性能计算器 (Performance Calculator) 来帮助判断给定用户基础/配置文件需要的磁盘子系统性能。您可以在以下站点获取性能计算器: HTTP://www.microsoft.com/Exchange/techinfo/planning/2000/ExchangeCalculator.asp
如果用户配置文件是未知的,那么就可以使用一些常用的准则,这些准则基于产品开发组在高峰负载期间,所观察到的每个用户每秒对 Exchange 数据库 I/O 的随机数趋势。这些准则仅适用于在数据库驱动器上产生的 I/O 数量(其他所有 Exchange 专用 I/O,包括日志驱动器,均不包括在内):
高级知识工作者配置文件 = .5 IOps
| • | 一台 3000 名用户的“高级知识工作者”服务器,可以监控对数据库驱动器的平均峰值随机磁盘 I/O(1500/秒)。 |
一般知识工作者配置文件 = .25 IOps
| • | 一台 3000 名用户的“一般知识工作者”服务器,可以监控对数据库驱动器的平均峰值随机磁盘 I/O(750/秒)。 |
注: 前例使用了“平均峰值”描述一天高峰时段(如 8:00 – 10:00)的平均数据库 I/O。数据库驱动器在这段时间必须能够处理随机磁盘 I/O 负载。不要混淆“平均峰值”和“峰值磁盘 I/O”。
从长期趋势看,OTG 了解,它的读/写配置文件大约是 3 次读操作对应 1 次写操作。当用户排序收件箱、查看电子邮件或打开电子邮件时,就会发生磁盘读操作。当用户撰写并发送电子邮件时,就会发生磁盘写操作。例如,发送一个带有 5 MB 附件的电子邮件就会有 5 MB 数据写入存储区。磁盘读操作本质上比磁盘写操作高效得多,这是因为有 RAID 配置。
确保数据库磁盘子系统可以支持所需的 I/O 级别。这是决定可以向服务器放置多少个邮箱的关键因素。观察并了解高峰服务器处理器使用的趋势。例如,假设一个支持 1500 个邮箱的服务器被设计成支持 2700 个邮箱。您就应该在一个时间段(如 24 小时)内观察其处理器的利用情况。查看备份情况(或许 RPC 峰值需要进行调查)和随后的稳定状态期(通过维护功能进行跟踪)。如果服务器趋势在工作日显示了 10% 的处理器使用,则显而易见,该服务器可以处理双倍的负载。
需要提醒的是,在您增加邮箱大小的同时,所需的磁盘传输(4K 随机读/写行为)也在增加。例如,在 OTG 原有的服务器配置中,支持 100 MB 的邮箱将每个邮箱每秒传输的持续高峰平均在 0.6 - 0.8 之间。在支持 200 MB 极限的新群集平台上进行的测试表明,在高峰时段的(一般为星期一上午)每秒传输明显增长到了 1.0 - 1.2。为了满足这一要求,OTG 设计了支持 4000 个 200 MB 邮箱的新平台,以支持高峰时每秒随机传输达到 6000 个 4K 并发读写操作时的延迟最小。
可用性/SLA 因素
如果公司因为电子邮件不可用而遭受巨大的收入损失,那么,Windows Server 2003 和 Exchange Server 2003 中的新群集功能可以有助于提供高可用性。OTG 的设计目标是每个 SAN 支持 8000 个邮箱,每个邮箱的大小为 200 MB,99.99% 的群集服务器可用,并且每个数据库备份及还原的时间不超过一小时。OTG 运行 16000 个邮箱的群集 SAN 实施,具有 99.9% 以上的服务可用性。
用于 Exchange 的 SLA 应该指定还原数据库的最大时间。这样可以限制每台服务器用户的数量。可以使用以下公式粗略估计每个数据库用户的数量:
每个用户的邮箱配额 (MB) × 用户数量 = 35000 MB/小时 × 还原的最大小时数
或者
用户数量 = (35000 MB/小时数 × 用于还原的最大小时数)/每个用户的邮箱配额
注:增加服务器容量也增加了每台服务器事务日志的数量。用于回复事务日志的时间也极大影响了用于还原服务器的时间。计算用于回复日志的时间,监控每天平均的日志数量,再相应调整恢复计划。
在规划和实施存储解决方案时所做的选择影响与管理维护 Exchange Server 2003 环境相关的成本。在规划 Exchange Server 2003 存储策略时,应该平衡以下 3 项标准:容量、性能和可用性。
| • | 容量。 在 Exchange Server 2003 中,总邮箱容量应该粗略等于邮箱数量乘以分配给每个邮箱的存储量,再加上 40% 的额外空间用于增长和保留删除文件。如果组织支持公用文件夹,还必须加上适当数量的磁盘空间,以用于公用文件夹存储。 |
| • | 性能。 根据吞吐量测量存储性能与测量一个存储设备每秒可以执行多少次读操作和写操作。 |
| • | 可用性。 消息系统对电子邮件可用性级别的要求取决于公司的需求。总体可用性通过冗余增加。通过将服务器进行群集或执行独立冗余磁盘阵列 (Redundant Array of Independent Disks,RAID) 解决方案来提供数据冗余。 |
在考虑合并时,需要决定为驻留 Exchange 的卷使用哪种类型的 RAID 级别。当前行业最佳实践是使用尽可能多的轴,并使用 RAID 0+1 进行配置,以获得最佳性能。RAID 0+1 应该用于数据库卷,但也可考虑用于事务日志卷。该设计为访问事务日志时的灾难恢复提供了最佳性能。
将系统设计为便于增长和优化
将连续和随机的 I/O 移至独立的逻辑单元号码 (Logical Unit Number,LUN) 分配或磁盘分配上。为了获得最佳性能,随机存储的数据应该独立于连续存储的日志驱动器。
监控日志驱动器和数据库驱动器上的可用空间。扩展时间段上的可用空间不得低于 40%。查看数据库日志文件,并且不允许其增长超过定义的极限。
将备份磁盘 LUN 置于独立的群集资源组中
备份磁盘是在一个分隔的群集资源组中进行维护的,从而在第一阶段的磁盘到磁盘备份和第二阶段的磁盘到磁带备份之间启用群集节点间独立的 LUN 活动。
注:Windows Server 2000 和 Windows Server 2003 群集将资源组织到功能单元中,即被称作资源组,它们被分配到单个节点。 如果一个节点发生故障,群集服务就将那些被该节点托管的组传输到该群集中的其他节点。该传输过程被称作故障切换。当故障节点再次激活时,就会出现相反的过程,即故障回复,那些被切换到其他节点的资源组即被传输回原节点。
设置高峰时段流量速率的基线
在设计新的 SAN 实施以前,OTG 需要了解现有 Exchange 实施的高峰 I/O 的需求是什么。OTG 收集该数据的最佳方法是在每周一上午(用户消息活动的高峰时段)记录消息基础架构活动日志。OTG 收集关于高峰时段流量的信息,查看趋势,再增加 20%,并将该数据作为规划未来增长的基线。OTG 建议将最忙服务器中的高峰使用计数作为规划负载扩展或服务器合并的基线。
在群集中使用卷装入点
OTG 群集服务器配置使用 SAN 最大化存储容量,并提高备份和还原性能。群集实施中对装入点的支持是 Windows Server 2003 中的新增功能。OTG 使用装入点消除驱动器盘符限制,以在大型群集邮箱服务器设计中支持日志、SMTP 和备份驱动器。
OTG 群集设计规范
OTG 实施与在 Exchange 2000 Server 中实施的相同类型的基础架构设计。然而,现在每台服务器仅使用 3 个驱动器盘符,而不是 10 个,以启用每台服务器中全部 4 个存储组关联,并使一个群集中能容纳更多的服务器。在 OTG Exchange 服务器上使用卷装入点意味着 4 个驱动器盘符可以有效支持 20 个数据库,而不是用 10 个驱动器盘符支持 15 个数据库。
较小区域群集实施的服务器规范由 1 个企业虚拟阵列 (Enterprise Virtual Array,EVA) 、3 个主动节点、1 个首要被动节点、以及 1 个备用被动节点 (AAAPp) 组成。
较大的总部群集实施在设计方面有些类似。它的组成如下:每个群集 2 个 EVA、4 个主动节点、1 个首要被动节点,以及 2 个用于进行从磁盘流备份至磁带的备用被动节点 (AAAAPpp)。这些配置如表 6 所示。
表 6 群集设计规范
| 规范 | 区域 | 总部 |
4 CPU 主动节点 | 3 | 4 |
4 CPU 被动节点 | 1 | 1 |
2 CPU 备用被动节点 | 1 | 2 |
EVA | 1 | 2 |
每个群集的邮箱 | 8,000 | 16,000 |
被动节点提供两个好处 —— 作为故障切换解决方案与用于备份过程中的独立资源。 首要被动节点支持高峰时段故障切换。备用被动节点主要用于将基于磁盘的备份传到磁带,使主动节点可以完全致力于服务用户。备用被动节点还提供非高峰时段的故障切换支持,以加速滚动升级或补丁应用程序的过程。包含 16000 个邮箱的总部实施设计如图 6 所示。
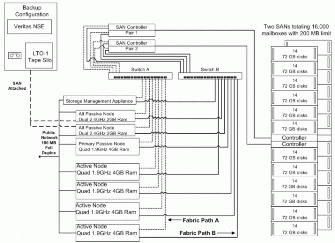
OTG 多节点群集设计是基于主动和首要备用服务器,具有 4 个超线程、1.9 GHz 的处理器,4 GB 的 RAM。这些服务器运行 WindowsServer 2003 Enterprise Edition 和 Exchange Server 2003 时进行了以下修改:
| • | Boot.ini 文件中的 /3GB 开关设置 |
| • | Boot.ini 文件中的 /USERVA=3030 参数设置。 |
| • | 使用装入点减少驱动器盘符限制,用于支持日志和备份驱动器。 |
| • | 在单独的群集资源组中维护备份磁盘,以启用群集节点间独立的 LUN 活动。 |
每台 Exchange 虚拟服务器 (Exchange Virtual Server,EVS) 托管 4 个存储组,使每台 EVS 总共可以容纳 20 个 50 GB 的数据库。每个数据库配置为具有 200–MB 的邮箱极限。该设计意味着每个数据库最多可容纳 200 个邮箱,即每个 EVS 容纳 4000 个邮箱,或者说总共可容纳 16000 个邮箱。
备用被动节点配置是更经济的服务器,它具有 2 个 2.4 GHz 的 CPU,2 GB 的 RAM。这些节点将基于磁盘的备份文件从基于磁盘的备份传到光纤连接的 LTO-1 Tape Silo。这两步备份过程的第二部分是使用 Veritas Network Storage Executive 进行管理的。
这些配置都是基于 Microsoft 内部消息系统需求。尽管这些配置(包括服务器和存储器)都是经挑选用于进行 Microsoft 部署的,但它们可能并不满足您的部署需求。通常,在进行任何 Exchange 部署以前都需要仔细地分析、规划、测试并进行试验。确保在决定自己的设计时采用了 Microsoft 和硬件厂商的最佳实践与推荐。
使用 Jetstress 测试磁盘性能
Exchange Server 2003 是一个磁盘密集的程序,它需要一个快速可靠的磁盘子系统以获得最佳性能。在开发部署以前,应该根据已建立的用户数量和用户配置文件的具体性能标准,使用 Jetstress 测试并检验磁盘子系统的性能和稳定性。
Jetstress 通过模拟 Exchange 磁盘 I/O 负载来帮助检验磁盘性能。Jetstress 可以明确地模拟出由一定数量用户产生的 Exchange 数据库和日志文件负载。您可以将性能监视器 (Performance Monitor)、事件查看器 (Event Viewer)、ESEUTIL 与 Jetstress 结合使用,以验证磁盘子系统是否满足或是超过了您所制定的性能标准。
注:查找 Jetstress,请访问: http://www.microsoft.com/exchange/tools/2003.asp
使用 Jetstress,可以执行两种类型的测试:Jetstress 磁盘性能测试 (Jetstress Disk Performance Test) 和 Jetstress 磁盘子系统压力测试 (Jetstress Disk Subsystem Stress Test)。磁盘性能测试运行 2 个小时,您可以验证存储解决方案的性能与大小。磁盘子系统压力测试运行 24 小时,您能在一段较长的时间内测试存储的可靠性。OTG 建议运行这两个测试来验证磁盘子系统的完整性和性能。
在运行测试以前配置磁盘子系统。使用以下清单做好准备工作:
1. | 检验 Windows 硬件兼容列表 (WHCL) 中列出的有关存储器的所有方面,该表可以从 http://www.microsoft.com/whdc/hcl/default.mspx 获得。
| ||||||||||||
2. | 确保驱动器/固件是最新的,包括(但不局限于):
| ||||||||||||
3. | 验证 HBA/SAN 特定配置是否正确设置。许多 HBA 使用注册表项将配置设置为适合特定的 SAN。 | ||||||||||||
4. | 配置存储 LUN(Exchange 日志设备和数据库设备)。 | ||||||||||||
5. | 在 Window 中使用 NTFS 格式化 LUN(默认分配大小)。 |
应该创建恰好与预期数据库大小匹配的 Jetstress 数据库。例如,Microsoft 职员通常每天只访问数据的某一部分。在某一周中,大多数用户可能不会访问 200 MB 邮箱中的所有数据。然而,Jetstress 将访问存储组中的所有内容。假设有一个 100 MB 的邮箱,并且有一用户访问产品存储组中 20% 的数据,需要构建一个至少 20 GB 的 Jetstress 数据库来表示 100 GB 存储组的使用模式。
获得关于 Jetstress 和其他可用于测试 Exchange Server 2003 性能和可伸缩性工具的更多信息,请参阅“计划 Exchange 2003 消息系统”: http://www.microsoft.com/downloads/details.aspx?FamilyId=9FC3260F-787C-4567-BB71-908B8F2B980D&displaylang=en
注: 只有与 Exchange 2000 Server 或 Exchange Server 2003,或更新版本的 ESE.DLL 一起运行时,Jetstress 才能得到支持。而且,由于这种支持限制,只有在 Windows 2000 Server、Windows Server 2003、Advanced Server、Datacenter 或更新的 Windows 操作系统平台上,Jetstress 才得到支持(Windows NT 4.0 和早期版本不支持 Jetstress)。
Exchange 使磁盘子系统得到了广泛应用,但其用途随着磁盘的目标功能而变化:
| • | 临时磁盘 |
| • | 数据库磁盘 |
| • | 事务日志磁盘 |
| • | SMTP 队列 |
| • | 页面文件磁盘 |
因为每种专门针对一种功能的磁盘显示了清楚的 I/O 使用,所以,一种磁盘应该只用于一种功能,以便于性能分析。
临时磁盘
操作系统临时驱动器是所有格式进行转换(如从 RTF 转换到 HTML)的地方。它也是在内容索引爬行遍历过程中创建的所有临时文件存储的地方。
在首次安装时,操作系统将临时文件设置为在操作系统所在的磁盘中创建和使用。这意味着临时磁盘的所有 I/O 将与运行驱动器和页面文件操作中的程序的 I/O 竞争,这会影响到性能。OTG 建议将临时磁盘设置为其自己的磁盘。这可以通过将全局环境设置改为“临时”,指向另一个磁盘来完成。
监控临时磁盘争夺,需要监控:
PhysicalDisk\Average Disk sec/Read。Average Disk sec/Read 是从磁盘进行数据读取操作的平均时间(以秒为单位)。该值的平均数应小于 10 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk sec/Write。Average Disk sec/Write 是向磁盘进行数据写入操作的平均时间(以秒为单位)。该值的平均数应小于 10 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk Queue Length。Average Disk Queue Length 是取样间隔期间排入选定磁盘的读取和写入请求的平均数。 该平均值应小于其磁盘的轴数(如果它实际是个物理磁盘,则该值为 1)。
数据库磁盘
Exchange 数据库由一个 EDB 文件(MAPI 内容)和一个 STM 文件(非 MAPI 内容)组成。EDB 文件保存存储过程使用的所有 MAPI 邮件和表格,以定位所有邮件、EDB 和 STM 文件的检验,以及 MAPI 邮件。STM 文件包含与本机 Internet 内容一起传送的邮件。因为对这些文件的访问通常是随机的,所以将它们放在相同的磁盘卷上。 监控数据库磁盘争夺,需要监控:
PhysicalDisk\Average Disk sec/Read。Average Disk sec/Read 是从磁盘进行数据读取操作的平均时间(以秒为单位)。该值的平均数应小于 40 ms。峰值(最大值)不应该超过 100 ms。
PhysicalDisk\Average Disk sec/Write。Average Disk sec/Write 是向磁盘进行数据写入操作的平均时间(以秒为单位)。该值的平均数应小于 40 ms。峰值(最大值)不应该超过 100 ms。
PhysicalDisk\Average Disk Queue Length。Average Disk Queue Length 是取样间隔期间排入选定磁盘的读取和写入请求的平均数。该平均数应小于其磁盘的轴数。
事务日志磁盘
事务日志文件维护 EDB 和 STM 文件的状态和完整性;这意味着该日志文件真正表示数据。每个存储组都有一个事务日志文件设置。要监控日志磁盘争夺,需要监控:
PhysicalDisk\Average Disk sec/Read。Average Disk sec/Read 是从磁盘进行数据读取操作的平均时间(以秒为单位)。该值的平均数应小于 5 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk sec/Write。Average Disk sec/Write 是向磁盘进行数据写入操作的平均时间(以秒为单位)。该值的平均数应小于 10 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk Queue Length。Average Disk Queue Length 是取样间隔期间排入选定磁盘的读取和写入请求的平均数。该平均数应小于其磁盘的轴数。
Database\Log Record Stalls/sec。Log Record Stalls/sec 是日志记录数,由于缓冲区已满,因此无法被添加到日志缓冲区(每秒)。该值的平均数应小于 25 ms。峰值(最大值)不应该超过 250 ms。
Database\Log Threads Waiting。Log Threads Waiting 是等待将数据写入日志文件的线程数,以完成数据库的更新。如果该值过高,该日志可能成为一个瓶颈。该值的平均数应在 10 以下。
SMTP 队列
在 SMTP 邮件被写入(私有或公用)数据库、或被发送至其他的服务器或连接器之前,它们都由SMTP 队列存储。SMTP 队列一般进行随机的小范围 I/O。监控 SMTP 队列,需要监控:
PhysicalDisk\Average Disk sec/Read。Average Disk sec/Read 是从磁盘进行数据读取操作的平均时间(以秒为单位)。该值的平均数应小于 10 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk sec/Write。Average Disk sec/Write 是向磁盘进行数据写入操作的平均时间(以秒为单位)。该值的平均数应小于 10 ms。峰值(最大值)不应该超过 50 ms。
PhysicalDisk\Average Disk Queue Length。Average Disk Queue Length 是取样间隔期间排入选定磁盘的读取和写入请求的平均数。该平均数应该小于其磁盘的轴数。
页面文件磁盘
页面文件通常可以显示某些使用情况,甚至在具有大量可用内存的计算机中:操作系统只试图将必需的页面文件保存在内存中,并为操作保留更多的可用空间。在物理内存被大量使用的服务器中,确保对该页面文件的所有访问尽可能快,这一点非常重要。服务器在页面文件已满之后开始在内存中查找错误,这种情况较为常见,因此,观察它的使用模式比它已满的程度重要得多。要监控页面文件磁盘争夺,需要监控:
PhysicalDisk\Average Disk sec/Read。Average Disk sec/Read 是从磁盘进行数据读取操作的平均时间(以秒为单位)。该值应始终低于 10 ms。
PhysicalDisk\Average Disk sec/Write。Average Disk sec/Write 是向磁盘进行数据写入操作的平均时间(以秒为单位)。该值应始终低于 10 ms。
PhysicalDisk\Average Disk Queue Length。Average Disk Queue Length 是取样间隔期间排入选定磁盘的读取和写入请求的平均数。该平均数应该小于其磁盘的轴数。
Paging File\% Usage。% Usage 表明在取样间隔期间使用的页面文件的数量,以百分比表示。高值表明您可能需要增加 Pagefile.sys 文件的大小或增加更多的 RAM。该值应低于 50%。
管理最佳实践
OTG 使用基于 MOM 基础架构的集中式管理进行全球数据中心监控。OTG 监控基础架构是由多个组构成的,这些组使不同的 Microsoft 小组能够获取他们想要的数据。例如,OPS 小组使用硬件和操作系统事件流,企业安全 (Corporate Security) 小组使用并存档安全事件流,信息操作小组则使用 Exchange 警告和性能信息的事件流。OTG 使用事故管理通知系统连接到 MOM 数据,以及 TSG 和其他内部信息。
使用 MOM 管理包监控 Exchange 2003
与 Exchange Server 2003 一起提供的还有一个新的 MOM 管理包,它使 MOM 能提供附加的端到端服务器监控。针对 MOM 的 Exchange Server 2003 管理包提供近 200 个新的即用规则,还有一个内置的 Microsoft 知识库,以监控并提前发出关于 Exchange Server 2003 性能、可用性及安全性方面的警告。良好的信息有助于快速故障检测、减少故障解决的时间并降低管理的复杂度。此管理包还包括对病毒监控和移动服务(如 Exchange ActiveSync 和 Outlook Mobile Access)的支持,使 OTG 能够在监控服务器性能以外,还监控的 Outlook 2003 客户端使用情况。
即用规则
其中一个有用的即用规则是标题为 Exchange 2003 Verify Log Files Are Being Truncated的 Exchange 事务日志老化脚本。该规则检测超过 24 小时的日志文件,这表明有一台服务器没有成功完成它的日常备份。该规则向消息操作组发送警告,如果需要,消息操作组再指派一个区域服务器所在位置的 IT 人员进行调查并备份该服务器。
OTG 使用的另一个有用规则是 Check Local Free Disk Space ,它现在支持群集装入点磁盘。群集上的装入点支持是 Windows Server 2003 中的新增功能,也是 OTG 用来扩展大型(16000 个邮箱)群集服务器中每个群集上虚拟服务器数量所必需的。
管理包中的规则还用于监控系统上的磁盘延迟。如果磁盘子系统不能有效处理系统需要的 I/O,就会基于磁盘延迟阈值发出一个警告。
自定义规则
如果事务日志超过 24 小时,标准 MOM 处理规则就发送一个警告,指示可能发生了备份故障。然而,为了支持高可用性和业务持续性,OTG 操作人员运行一个自定义处理规则,该规则检查当地时间每晚 20:00 - 20:10(安排备份的时间)之间的应用程序事件日志,以查找丢失的事件。如果没有事件存在,备份可能一直未开始,并且操作人员会立即收到通知。OTG 还使用一个自定义合并规则,以检测给定时段内成功备份的数量。如果该数量低于预期的值,将会发生警告提醒操作人员进行调查。
自定义报告
自定义报告补充管理包的即用报告。例如,OTG 从一个长期趋势数据库中监控趋势度量,该数据库中包含诸如服务器可用性、可用空间计算、以及发送和接收邮件总数等数据。图 7 是 OTG 从数据库查询中提取的一个自定义报告示例。
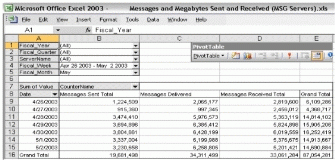
该示例报告包含了 OTG 在 Microsoft 所有内部邮箱服务器获得的 3 个性能计算器:
| • | 发送的邮件总量 (Messages Sent Total)。 从服务启动开始通过 SMTP 传输协议发送的所有邮件。 |
| • | 送达的邮件 (Messages Delivered)。 成功送达至信息存储区的邮件。 |
| • | 接收的邮件总量 (Messages Received Total)。 通过服务器或存储区接收到但仍未送达的邮件。 |
该数据透视表使 OTG 可以按日期、财政周、财政月以及单台服务器查看发送、送达和接收到的邮件数量。此示例显示了 4 月 26 日至 5 月 2 日这一财政周内发送、送达和接收的邮件数。
MOM 应用程序管理包中对 Exchange 的支持已扩展至涵盖 1800 条针对群集和非群集 Exchange 服务器的 Exchange 2000 Server 事件,并提供高级的邮箱和 Outlook 客户端性能测试。
查找 Exchange 2003 管理包,请访问
http://www.microsoft.com/downloads/details.aspx?FamilyID=56d036bf-8dd3-4993-bf07-07f99f1d5cc4&DisplayLang=en
获取关于 Exchange 2003 Management Pack for Microsoft Operations Manager 的更多信息,请访问: http://www.microsoft.com/mom也可查阅白皮书“在 Microsoft 监控企业服务器”,请访问 http://www.microsoft.com/technet/itsolutions/msit/operations/entserv.mspx
自定义阈值级别
管理包中所提供的阈值定义与各种大小的服务器有关。由于 OTG 以单一服务角色运行服务器,所以每台服务器的邮件流级别都存在很大差异。您应该将每小时可以处理数千封电子邮件的 Internet 网关服务器,作为一个队列管理的独立实体。根据业务调整阈值规则。
例如,OTG 有一个处理未送达流量的网关服务器。OTG 指定一个与该服务器关联的大幅调整的阈值集。在不处理未送达流量的网关服务器上设置了更低的阈值定义。例如,OTG 在 In, , ternet 网关服务器队列上建立了 10000 – 15000 封邮件范围的阈值规则,而对于邮箱服务器,OTG 则建立了一个仅 500 封邮件的阈值规则。
要修改即用规则,应该先禁用该规则,再将它复制到一个自定义处理的规则组中,最后在该自定义规则组中调整它的阈值定义。这种方法可以使原规则保持完好无损,并且能更有效地管理更新。
此外,应该为服务器建立长期的趋势特征(如处理器使用、磁盘 I/O 和 RPC 延迟),再在环境中设置定义一个非正常情况的阈值。在调整阈值以后,准备跟踪并调查环境中出现的变化。例如,处理器使用率正常情况是 40%,如果它在持续的一段时间段内窜升至 80%,那么就可能存在问题。
容量管理
容量管理是对服务解决方案进行规划、调整大小并进行控制的过程,以达到或超过定义服务级别协议所规定的性能级别。服务器和网络容量是整体容量的关键组成部分。IT 操作人员可以在 MOM 管理包中设置预先的阈值,它将指示在什么时候需要额外的容量
根据 OTG 在监控关键容量指示器方面的经验,您应该监控:
| • | 邮箱服务器的 RPC 延迟 |
| • | 邮箱服务器的磁盘延迟 |
此外,容量规划中经常被忽视的要素是操作过程本身。经多次部署用于提供服务解决方案的过程不会随着用户数量的增加而被重访,除非该过程的某个地方出现问题。根据 OTG 的体验,深入分析经常会发现那些满足少量用户或某个测试环境的过程不能进行扩展以支持增加的负载。应该使用传统的消息系统参数定期检查过程扩展。
平均 RPC 延迟的趋向
如果 RPC 平均延迟一直很高,它就会影响客户端性能。高 RPC 未解除的请求和操作(每秒)通过 RPC 请求和 RPC 操作(每秒)计数器指示。
此处提供的数据是基于 OTG 早期使用者经验的示例,而不是通用的推荐。OTG 经常监控 MSExchangeIS 对象上的以下计数器,以进行容量管理:
RPC Operations/sec。该计数器并不能单独清晰地显示服务器的繁忙程度,因为处理器除受到日常电子邮件处理的影响以外,还可能受到服务器其他方面的影响。每种操作都向服务器带来不同的负载;有些昂贵,有些则不然。如果进行了大量的昂贵操作,服务器可能会超载。 如果每秒的 RPC Operation 较低并且未完成的请求计数器 (MSExchangeIS\RPC Requests) 为 “0”,那么该问题点是在 Exchange 之前 —— 其他所有情况的组合都显示该问题点是在 Exchange 本身或在 Exchange 之后。
RPC 平均延迟。RPC 平均延迟持续保持在 50ms 以上表明客户端性能较低。
RPC 请求。20 – 25 RPC 请求指示该存储过程在累积。
监控磁盘读取与写入延迟
磁盘读取延迟与磁盘写入延迟能显示出该磁盘的运行情况。每个 I/O 磁盘传输是一个 4 KB 的块。每秒 5000 次 I/O 乘以每个 I/O 块的 4 KB 即是每秒 20 MB 数据的总传输速率。它是通过 Disk Transfers/sec 计数器显示的。
在 PhysicalDisk 对象上,OTG 监控:
| • | Avg. Disk sec/Read。 磁盘读操作平均延迟的正常范围低于 16ms。 |
| • | Avg. Disk sec/Write。 可接受平均 2ms - 4ms 的延迟。 |
| • | Disk Transfers/sec。 这是每秒的传输总数。在延迟最小化后,此处可接受任何值。OTG 一般观察 5000 个峰值,包括 66% 的读操作和 33% 的写操作(带有 2ms - 4ms 的写操作延迟)。 |
SAN 磁盘管理
您应该设置可用磁盘空间监控阈值,从而在可用磁盘组空间降至 10% 以下时发出警告。如果决定必须向 EVA 中增加额外的磁盘空间,通常将它们按偶数个数进行添加。
通常需要在所有层上均匀地增加磁盘容量 — 使每个层上的磁盘数对等。磁盘每次插入以后,至少等待 60 秒,以让控制器软件完成设备识别。
监控 PF/FB 性能
当使用 Exchange 缓冲模式时,普通 Outlook 2003 用户任务的 90% 都是在后台执行的。然而,仍有些需要实时访问的特殊任务,包括:
| • | 访问公用文件夹 |
| • | 委派邮箱访问(供那些有访问他人邮箱权限的人员使用,如帮助经理安排约会的行政助理) |
| • | 检查其他用户的忙/闲(用于检查预期会议邀请接收人的日程可用性) |
Exchange Server 2003 部署期间进行的 Exchange 服务器与主要区域站点的合并要求 OTG 部署容量更高的公用文件夹服务器,以保持所有用户性能级别的统一持续。OTG 预测这些服务器使用率会更高,因为每台服务器上会有更多的人使用忙/闲发布、检索 Outlook 2003 安全设置,以及访问常规公共文件夹和预合并。每个合并站点部署两个非群集的公用文件夹服务器进行冗余和分载。
可用性管理
可用性管理 SMF 的目标是确保服务用户能够根据 SLA 项访问提供的 IT 服务。 例如,3 – 5 个 9s 的可用性目标,也是指在一年中进行的 7x24x365 次操作中,存在 525 – 5 分钟的意外故障时间。
可用性与可靠性有关,但又区别于它。可靠性度量系统发生故障的频率,而可用性度量系统处于运行状态的时间百分比。计算可用性的常用方法是从总时间中减去故障时间,再将它除以总时间。例如,如果数据中心平均每 6 个月发生一次故障,且将数据中心恢复到运行状态的平均时间是 20 分钟,那么该数据中心的可用性为:
可用性 = (6 个月- 20 分钟)/ 6 个月 = 99.992%
然而,仅测量 服务器 运行时间是不充分的。存储区脱机将可能导致 Exchange 停歇,但相应的服务器不会停歇。OTG 消息小组根据停止事件和相应启动事件之间的持续时间计算指定服务器的 服务 可用性度量,再将它乘以数据库个数,以帮助优先响应。例如,对 15 个数据库用户的 1 分钟停歇就被报告为 15 分钟的故障时间。
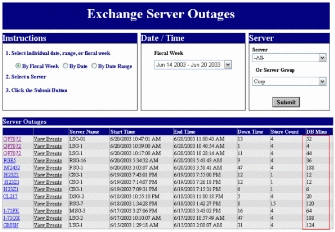
OTG 使用 MOM 收集数据库中所有的停止事件和启动事件。内部 Web 站点从事件日志中提取事件流。然后站点然后执行查询,查看每个停止事件并查找相应的后续启动事件,记录停歇持续时间(被称作“数据库会议记录”,或者“DB Mins”),如图 8 所示。根据对用户的影响显示停歇帮助消息操作组进行有目的地回复。
病毒和垃圾邮件管理
您应该在网关处筛选电子邮件病毒和大部分垃圾邮件。长期趋势表明,Microsoft 40 – 70% 的入站电子邮件都是垃圾邮件。OTG 不对这些邮件进行传输,而是在网关处对它们进行拦截,以节省网络和硬件资源。
防病毒服务器是在电子邮件到达存储区以前在网络外围对其进行筛选的网关服务器。使用 MOM 检测防病毒服务的可用性。例如,OTG 在每台防病毒服务器上每隔几分钟就运行一次服务验证 (Service Verification) 脚本,以确保防病毒服务在运行。如果该服务不在运行,MOM 即发出警告。为了其他方面的安全,OTG 要求在每个企业标准桌面上运行其他的防病毒软件。
通过检查从邮件中删除的病毒数量调整阈值定义规则。例如,OTG 每隔几分钟就抽样被删除病毒的数量。如果在 5 次抽样期间,病毒队列都超过 100,就会发出警告。测量规则可以帮助 OTG 了解该环境中接收邮件、发送邮件、发送病毒,以及被处理的感染邮件总数的趋势。该措施有助于在发生某种类型拒绝服务攻击的情况下发出预先警告。
获取关于 Exchange Server 中防病毒措施的通用信息,请参阅《Exchange 2000 Server 操作指南》中的“保护”章节。
强制 OWA Server 邻近性
OTG 早期使用者的经验表明,为了获得最佳性能,应该鼓励用户选择物理上离他们邮箱服务器最近的 OWA 前端服务器,而不是离他们所在位置最近的 OWA 服务器。例如,一名职员从澳大利亚出差至美国,如果 WAN 连接是她与 OWA 服务器之间,而不是 OWA 服务器和她的邮件服务器之间,那么她的在线 OWA 体验就可以进行优化。为了方便用户,OTG 修改了 OWA 登录界面,在其中包括了到所有可用 OWA 服务器的链接,并包括如何使用每一项的指南,如图 9 所示。
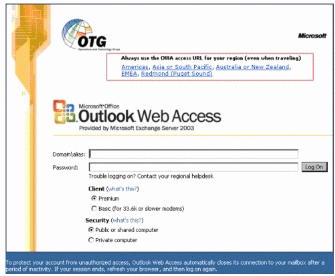
Outlook Web Access 的新登录页面将用户的名称和密码存储在 cookie 中,而不是存储在浏览器中。当用户关闭浏览器时,该 cookie 即被清除。此登录页面还允许用户选择最适合他们需求的安全选项。公用或共享计算机选项(默认选择的)提供较短的默认超时(15 分钟)选项。或者,在办公室或作为家中唯一计算机操作者的 OWA 用户可以选择专用计算机选项。该项被选中时,即会在结束会话以前提供一个更长的休止期,默认情况是 24 小时。为了满足企业的安全需求,Exchange Server 2003 管理员可以为这两个选项设置自定义休止超时值。要启用 Outlook Web Access 登录页面,必须启用服务器上基于窗体的认证。
仔细规划 Exchange 连接名称
用于 OWA 的同一 Exchange 前端服务器也被 OTG 配置中的 Outlook Mobile Access (OMA) 用户使用。考虑到通过一个 Smartphone 设备进入一个普通的 URL 可能很费时间,因此一个长而复杂的 OMA URL 很可能会妨碍大多数用户正常使用该服务。
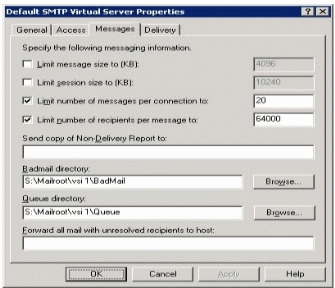
SMTP 队列目录管理
Exchange Server 2003 支持用以移动 SMTP 死信和 Queue 目录的 GUI 新方法。这使得为“多用途” Exchange 服务器上的 SMTP 队列使用专用磁盘具有可行性。例如,OTG 为服务器(集线器和公用文件夹服务器的混合)上的 SMTP 队列和死信目录分配专用的磁盘轴,而不是使用默认的 Exchange 安装驱动器。使用专用磁盘提升了服务器性能、磁盘空间管理,并且使在 Exchange 2000 Server 中通过移动目录排除故障比以前更容易。GUI 中的变化如图 10 所示。
业务连续性管理
业务连续性 SMF 以前也被称为应变管理,它与可用性密切相关,专注于通过规划 IT 灾难中的响应和恢复来最小化关键任务系统的业务中断。
IT 灾难被定义为一种延长时段的服务损失,它要求将工作以非常规方式转移到备用系统上。并且通过前瞻与回应匹配的开发和介绍来指导对现有系统的保护。IT 服务连续性管理还考虑需要在服务停歇的事件中执行什么活动,而不是把它归为一个无药可救的灾难。
业务连续性管理的关键是制定(与维护)一个有效的服务连续性(应急)计划,其中包括:
| • | 备用的操作站点和/或能够运行关键业务系统的备份设施 |
| • | 可以在主要服务中断的事件中执行的手工备份或备用业务处理 |
| • | 关键业务系统的高可用性最佳实践(冗余、热/温/冷备用系统、镜像等) |
| • | 在应急计划执行过程中,具有用于协调活动的清晰流程和沟通渠道;建立指挥中心 |
| • | 关键恢复计划中人员的培训 |
| • | 可靠、有效的日常备份对业务连续性计划的成功至关重要。图11 显示了一个 Exchange 2000 Server 灾难恢复流程图的示例。 |
使用两步备份过程
OTG 在其群集环境中使用两步备份过程 —— 磁盘到磁盘和磁盘到磁带。以前,这两步都是通过运行 Exchange 的邮箱服务器进行管理的,这会影响服务器性能。也因为这种影响,OTG 曾使用一个限制的窗口来进行日常备份。现在,使用 Exchange 和 Windows 中的群集改进,OTG 可以在备用被动节点上执行该过程中的步骤 2(磁盘到磁带),这将用户受到的影响降至最小。该设置还可使 OTG 更灵活地根据需要在不同时间运行备份。
获取关于 OTG 两步备份过程的更多信息,请参阅技术案例研究“Microsoft 的消息备份和还原”,请访问 http://www.microsoft.com/technet/itsolutions/msit/operations/msgbrtcs.mspx
使用 MOM 监控备份和还原
OTG 每晚执行所有依赖于服务器的 15 – 20 个数据库(平均 20 GB - 50 GB)的备份。 这些数据库被表示为一个具体的 BKF 文件存入预定义的目录中,使多并发备份工作可以在第二阶段备份中完成。
如果事务日志超过了 24 小时,标准 MOM 处理规则就发送一个警告,指示可能发生了备份故障。然而,OTG 还运行一个自定义的 MOM 处理规则,该规则检查当地时间每晚 20:00 - 20:10(安排备份的时间)之间的应用程序事件日志,以查找指示预定备份已开始的丢失事件。如果该事件不存在,操作人员会立即收到警告。OTG 还使用一个合并规则,以检测给定时段内成功备份的数量。如果该数量低于预期的值,将会发生警告提醒操作人员进行调查。
在使用 MOM 管理包监控群集时,应该禁用日志复制,以防止从物理群集节点复制警告。
使用恢复存储组
Exchange Server 2003 恢复存储组用于灾难恢复还原,以及单个邮箱还原。如果发生了硬件故障并且丢失了数据库,在恢复用户原有数据时,您可以调用空的存储组。这样能迅速还原服务,同时使用户的故障时间最小化,但在还原操作的过程中访问的是旧数据。
问题的管理与支持
当环境中发现新类型的错误条件时,应该根据这些新类型来设置警告。在每个新条件执行一个警告和通知过程。为了使操作人员可以快速响应问题,通过编写 TSG 来记录该警告和通知过程。在 Microsoft,所有常见警告都有一个相关的 TSG ,即一个 5 至10 页的针对技术人员的 Microsoft Word 文档,它包括解决该问题的说明,以及如果补救方法不成功或分配的时间(以 15 分钟为例)已过期时,应采用的明确增强途径。例如:
| • | 如果该警告是针对 Exchange 的,它就会被逐层提交至消息操作组中的某个人。 |
| • | 如果该警告是与硬件相关的,它就会被逐层提交至操作组中的某个人。 |
| • | 如果该警告是操作系统问题,它就会被逐层提交至 IS 层级 3 技术支持组。 |
OTG 在一个基于 Windows SharePoint Service 和 SharePoint Portal Server 的内部站点上维护 TSG,如图 12 所示。
使用计数器定位故障
医学行业有个指导原则就是“首先,不产生危害” 。在试图解决某个问题以前,首先确保得到的是正确的信息。在一个复杂的 IT 环境中,修复错误的事物可能与不及时修复正确的事物具有一样的破坏性。要确保查看了相关的实时性能特征。
例如,监控 MSExchangeIS\RPC Averaged Latency 和 MSExchangeIS\RPC Requests 计数器,它们提供一个 Exchange 客户端性能视图。在收到警告时,通过手动查看服务器上的实时性能特征进行调查。查看处理器使用、物理磁盘计数器、网络接口计数器,以及 MSExchangeIS 对象 计数器。同时还需要查看线程(处理器计数器),看是否是某个过程出现了问题。
在 MSExchangeIS 对象上,RPC Operations/秒 计数器指示 RPC 请求处理的速率。 如果 RPC Operations/秒的数值较低,并且未解决的请求计数器 (MSExchangeIS\RPC Requests) 是“0”,那么该问题是在请求到达 Exchange Sever 之前出现的 —— 其他所有组合都指示该问题是在 Exchange 之中或在 Exchange Sever 处理这些请求之后发生的。
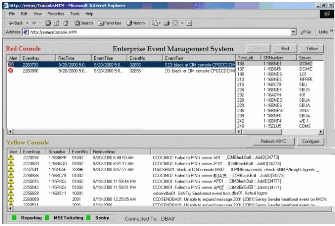
使用问题跟踪内部网门户
设置一个 Web 站点查看开放的故障通知。数据中心操作 (OPS) 使用称为企业事件管理系统 (EEMS) 的内部工具查看 MOM 警告。图 13 显示了一个 EEMS 屏幕,上面显示了控制和非控制的停歇、各自持续的时间,以及与相关事故通知和 TSG 的链接。
隔离问题
在试图解决或诊断问题时,要确保禁用、关闭或暂停了在线维护、反垃圾邮件、备份、监控、邮箱移动及远程访问工具。
安全性最佳实践
获取关于 Exchange Server 中安全性最佳实践的通用信息,请参阅《Exchange 2000 Server 操作指南》中的“保护”章节。其中建议的最佳实践也适用于 Exchange Server 2003。
使用安全性增强了的客户端
Outlook 2003 和 OWA 2003 提供防病毒增强功能,包括附件分块、自动脚本和 Web 信标消除。使用这些客户端,可以允许用户维护可信任的和垃圾邮件发件人 (Junk Senders) 列表,并可在服务器上选择性地存储可信任的/垃圾 (Trusted/Junk) 列表。
为了增加安全性,同时简化支持,您可以使用 Outlook 的早期版本对服务器进行分块访问。该操作需要 Exchange 2000 Server Service Pack 1 或更新的版本。获取更多信息,请查阅“安全提示:将服务器端限制放在用来访问 Exchange 2000 邮箱的客户端上”,请访问 http://www.microsoft.com/exchange/techinfo/tips/SecTip01.asp
启用基于窗体的认证
为了提高安全性,您可以为 Outlook Web Access 启用新的登录页面,它将用户名和密码存储在一个 cookie 中,当用户关闭浏览器时,或在预定义的浏览器为非活动状态之后,该 cookie 即失效。新的登录页面要求用户输入域、用户名和密码,或者完整的用户主要名称 (UPN) 电子邮件地址和密码。要启用 Outlook Web Access 登录页面,您必须在服务器上启用基于窗体的认证。
在 HTTP 上使用 RPC
作为使用 Outlook 客户端或 OWA 访问VPN的一种备用方法 ,您可以通过使用 RPC/HTTP的 Outlook 2003 为用户提供一个更为安全的邮件接收方法。Windows 2003、Exchange Server 2003、Outlook 2003 和 Windows XP Service Pack1 都是 RPC/HTTP 所必需的。在 HTTP 上部署 RPC 的推荐方法是在外围网络中安装带有 Feature Pack 1 的 ISA Server,并在企业网络中设置 RPC 代理服务器。RPC 代理服务器可以是 Exchange 前端服务器,也可以是允许用户从 Internet 进行连接的 Web 服务器。使用 RPC/HTTP,OTG 不需要在网络外围中开放新的端口,用户就能够获得全面的 Outlook 2003 功能,包括新邮件通知、公用文件夹访问、忙/闲信息以及更多内容。
过滤高配置文件发件人
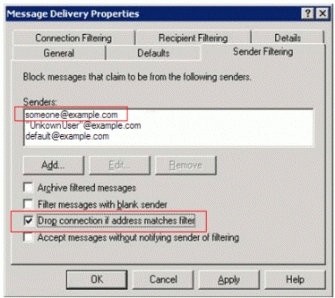
对您确信的、永远不会通过 Internet 发送邮件给您的特定内部发信者进行堵塞。例如,如果 CIO 从不通过 Internet 向内部企业消息系统发送电子邮件,就可将 CIO 地址 (someone@example.com) 作为一个入站 Internet 电子邮件的发件人进行堵塞。还应该堵塞那些由可轻易猜中的字母组成的通讯组名称,如 ops@example.com。这可以防止任何恶意代码或发件人试图冒充入站电子邮件的发件人。
通过选择 Message Delivery Properties 对话框中的 Sender Filtering 标签上的 Drop connection if address matches filter 功能来堵塞使用 Exchange ESM 的发件人,如图 14 所示。
使用仅经过认证的发布组
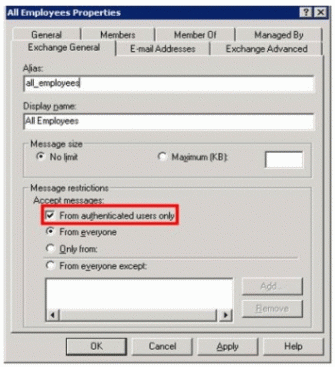
Exchange Server 2003 中的新增功能支持限制敏感发布组,从而只接受经过认证的发件人。如果可以决定某个通讯组永远不接收来自匿名发件人的电子邮件,您就应该将所有这种通讯组都限制为只接受来自经认证的发件人的电子邮件。该方法将减少从 Internet 发送到该通讯组的未经请求的商业电子邮件。
在查看“Active Directory 用户和计算机”中的启用电子邮件对象时,该功能是作为 All Employees Properties 对话框中的 Exchange General 标签来执行。 要查看该选项,必须安装 Exchange 2003 Management Components。图 15 显示了一个标签名为“All Employees”的示例发布组 (DG) 设置。
禁用 P2 发件人地址解析以防欺骗
在 Exchange 2000 Server 中,ResolveP2 注册表项包含 Exchange 2000 可用于解析电子邮件正文中具体邮件地址的信息(被称作 P2),前提是这些用户存在于 Exchange 2000 目录中。
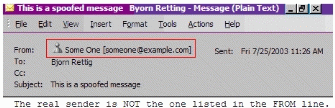
欺骗是一种使用假发送地址来掩盖邮件来源的行为。欺骗可能会将回复合法地重寄到真正发送该邮件的帐户以外的其他帐户,但它也可能用来冒充另一个发件人、恶意将回复重寄到垃圾电子邮件,或者获得对某个安全系统的非法进入。
如果双击客户端中的解析地址,Exchange 2000 或 Exchange 2003 目录信息就会显示出来。未解析的地址只显示SMTP 地址。因为该解析行为是针对内部地址的,所以外部解析的地址可能会导致不留心的电子邮件用户认为某封电子邮件是来自本地域或组织的。如果启用了 ResolveP2 设置,经过培训的用户就能够区分内部电子邮件与外部电子邮件之间的差异,如图 16 所示。
在 Exchange Server 2003 中,默认情况下,解析匿名 (P2) 电子邮件设置是未被选中的(禁用的)。可以在 Authentication 标签的 Access 标签下,在 SMTP Virtual Server Properties 的 Exchange System Manger 中启用匿名解析,如图 17 所示。
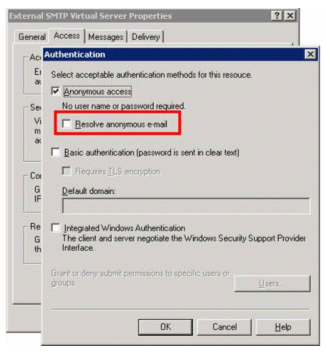
图 17 ResolveP2 设置标签
您可在从 Internet 上接收电子邮件的服务器上设置 ResolveP2 关键字。关于为 Exchange 2000 Server 设置注册表项的说明,可以从
http://support.microsoft.com/default.aspx?scid=kb;en-us;288635&sd=tech的知识库文章 288635 中找到。
结论
与其他企业 IT 组织一样,OTG 的操作目标集中在获得可用性、性能、灵活性与成本之间的良好平衡。唯一不同在于,OTG 经常在将 Microsoft 解决方案发布给公众以前,尽可能使用这些方案。取得的操作优势包括人员、过程和技术。
人员
OTG 中负责邮件处理环境的操作小组为了达到其目标,致力于以下几个主要方面:
A —— 与监控需求达成一致
D —— 部署过程和技术
O —— 优化过程和技术
P —— 执行连续监控
T —— 打开和关闭监控
S —— 向客户展现最佳实践和积累的经验
过程
Microsoft 操作管理器 (Microsoft Operations Manager) 上的单一监控基础架构、通知系统以及配置管理数据库都支持 OTG 过程。潜在服务违规的前瞻性监控和通知,以及在任何可能使用自动纠错功能的地方快速解决事故对取得 OTG 模型企业初期目标都至关重要。标准过程模型,如 Microsoft 操作框架,能够帮助企业运作持续改进。
技术
Windows Server 2003、Exchange Server 2003、Microsoft Office 2003 Editions 和解决方案(如 Microsoft Solutions for Management 和 Microsoft Operations Manager)中的增强使 OTG 能够不断地改进日常邮件处理操作。甚至是在一个极其多变的环境中, OTG 维护着:
| • | 平均每天 6000000 封邮件的全球邮件流量,同时平均每天还有 2500000 封 Internet 电子邮件。 |
| • | 全球服务可用性超过 99.9% 。 |
| • | 全球95% 邮件递送的时间都不超过 90 秒。 |
| • | 每个数据库用于备份和还原操作 SLA 的时间不超过 1 小时,甚至在具有 5000 多个 200 MB 邮箱的服务器和 16000 个邮箱的群集实现方案中也适用。 |
OTG 在其环境方面具有许多独特之处,同时它承担着在 Microsoft 软件向公众发布之前使用这些软件的义务。然而,许多早期使用者积累的经验和最佳实践也可能适用于其他的企业客户。OTG 将继续与其客户一起分享经验和建议,把它作为客户服务使命的一部分。
| 自由广告区 |
| 分类导航 |
| 邮件新闻资讯: IT业界 | 邮件服务器 | 邮件趣闻 | 移动电邮 电子邮箱 | 反垃圾邮件|邮件客户端|网络安全 行业数据 | 邮件人物 | 网站公告 | 行业法规 网络技术: 邮件原理 | 网络协议 | 网络管理 | 传输介质 线路接入 | 路由接口 | 邮件存储 | 华为3Com CISCO技术 | 网络与服务器硬件 操作系统: Windows 9X | Linux&Uinx | Windows NT Windows Vista | FreeBSD | 其它操作系统 邮件服务器: 程序与开发 | Exchange | Qmail | Postfix Sendmail | MDaemon | Domino | Foxmail KerioMail | JavaMail | Winwebmail |James Merak&VisNetic | CMailServer | WinMail 金笛邮件系统 | 其它 | 反垃圾邮件: 综述| 客户端反垃圾邮件|服务器端反垃圾邮件 邮件客户端软件: Outlook | Foxmail | DreamMail| KooMail The bat | 雷鸟 | Eudora |Becky! |Pegasus IncrediMail |其它 电子邮箱: 个人邮箱 | 企业邮箱 |Gmail 移动电子邮件:服务器 | 客户端 | 技术前沿 邮件网络安全: 软件漏洞 | 安全知识 | 病毒公告 |防火墙 攻防技术 | 病毒查杀| ISA | 数字签名 邮件营销: Email营销 | 网络营销 | 营销技巧 |营销案例 邮件人才:招聘 | 职场 | 培训 | 指南 | 职场 解决方案: 邮件系统|反垃圾邮件 |安全 |移动电邮 |招标 产品评测: 邮件系统 |反垃圾邮件 |邮箱 |安全 |客户端 |